


GPT-5 was the most anticipated model launch since GPT-4 – trailed by months of leaks, a Death Star teaser from Sam Altman, and the usual chorus predicting “a new era.” Technically, it’s sharp. Strategically, it’s shrewd. Directionally, it’s uninspiring. Reflecting on it 24 hours later, my conclusion is simply that the release is aimed squarely at improving margins and reclaiming developer mindshare from Anthropic, not at expanding what AI can do for science, health, energy, or anything that feels transformative. I know these developer tools and infrastructure improvements are necessary building blocks for bigger breakthroughs. But it's hard not to feel impatient when the marketing promises paradigm shifts and we get performance upgrades.
There’s plenty to be impressed by, and many influential developers, researchers, and CEOs have shared great feedback on the improvements. But there’s also a noticeable shrug; less because of the capabilities, and more because OpenAI tends to overhype. If you trail a Death Star, people expect tectonic plates to shift at the 10am livestream.
They did not.

I was full-on expecting to wake up on Thursday and ready myself for a new world order to come. Alas, the world remain as is:

I tried my own vibe check. On any given week of writing this newsletter, I do it mostly the old-fashioned way (gasps - I know - no AI assistance is the new hand-writing a novel!). Just for fun, I tried giving GPT-5 some prompts and drafts+half-written notes, plus many examples of my past writing via previous newsletters, to ask it to help me write this week’s. All I can say is YUCK. It reeked of AI slop. Delete delete delete.
You know what it is, because one cannot open LinkedIn, or even some newsletters out there, without sniffing the slop: It’s the barrage of em dashes (curse you, OpenAI, I used to fucking love them); it’s the “It’s not just X; it’s Y” construct; it’s the overuse of the word “quietly” (no, you simping model, Anthropic did not “quietly” release 4.1, there are 300 articles written about it quite loudly); it’s using the word “dropped” for every model release announcement; it’s all the cringe-y faux rhetorical questions for added drama.
I could go on. If it sounds like I am exasperated, it’s because I am. Not because AI couldn’t write this newsletter for me (all good bruv, I’ll type myself thank you very much 💁🏻♀️). But because it pointed to a world where actually nothing has really particularly improved besides for coding. I mean it’s faster, sure. OpenAI says it’s smarter; okay, I don’t feel it, but fine, it’s a little smarter and much faster. It’s definitely cheaper! But that’s a business decision. It is definitely better at coding, though. And that is the point. That is basically the whole point. I cannot help but feel deceived.
Good for you for one-shotting an entire web app in one go. Yay, the death of SaaS! Sooooo impressive. It’s soooooo over for all of software as we know it, says every thread scam artist in my feed. Cool. How lovely for us! Coding is math, friends. To be fair, I don’t say this to in any way undermine the absolute marvel that is the fact that for day-to-day production work, I think we’ve effectively “solved” coding. But the oft-promised AGI? Not even close. And if we keep at the current architecture and training approach, I’m not sure the promised wonders will arrive at all.
What I’m excited about — and what I’m not seeing — are the Machines of Loving Grace: AI discovering new molecules, reshaping energy systems, denting hunger, accelerating space exploration. Instead, we get benchmark gaming and a developer land grab. Nice for the scoreboard. Banal for the species.
I’m working in AI as an investor, despite the many misgivings I’d be a fool not to have, because I do so earnestly believe in the promise of the great good that is to come. But that is not what I am seeing.
Give me an AI scientist. Give me unlimited energy. Give me a lab that actually cares about that. I do not care that we can now create an SVG of a pelican riding a bike. That we can one-shot frontend design. We already have designers for that! I know these breakthroughs might require years more work on reasoning, tool use, and reliability. I know. I KNOW! But given the hype cycles and investment levels, it's frustrating that we're not seeing clearer progress toward these bigger goals. Someone please build something that has real meaning, and wake me up when that day arrives. And so, at least on my own benchmark, GPT-5 was an utter letdown.
/end rant
I don’t mean to throw so much shade; I’m in the business of money so I know quite well that to build things, we need to find a way to make them economically scaleable, and worth the investment. (And oh boy, have we spent a lot of it to get AI going). So of course the labs are working towards margin optimization. Of course they are trying to find ways to compete with one another for pools of consumer and enterprise spending. Money doesn’t fall from the sky.
All of it may be coming in due time. But it’s hard not to feel like the efforts could be much, much further along –
Ok, if you’re still with me, here is this week’s summary:
GPT-5
The release: GPT‑5 rolled out on August 7 to Free, Plus, Pro, and Team tiers, with Enterprise and EDU coming next week. It’s the new default in ChatGPT, replacing the patchwork of 4o, O1, O3, etc. The lineup spans gpt‑5, gpt‑5‑mini, gpt‑5‑nano, plus a non‑reasoning variant for lighter workloads. Pro users also get GPT‑5 Pro, the higher‑effort reasoning model.
Model architecture: GPT‑5 is a unified system fronted by a model router that decides when to use a fast path and when to engage the “thinking” model. The API supports ~272k input tokens and ~128k reasoning/output tokens (≈400k total). Controls include reasoning_effort (minimal, low, medium, high) and verbosity. Benchmarks show it at 94.6% on AIME 2025 (math, no tools), 74.9% on SWE‑bench Verified, 88% on Aider Polyglot coding, 84.2% on MMMU, and 46.2% on HealthBench Hard (this being my favorite / most interesting metric, as using ChatGPT as the new WebMD is apparently a really big use case).

Factuality and safety: OpenAI claims ~45% fewer factual errors than GPT‑4o in web‑style prompts, and ~80% fewer with reasoning enabled. Deception/sycophancy rates are lower than o3, supported by ~5,000 hours of red‑teaming under the Preparedness Framework. Safety updates include “safe completions” that aim for partial but accurate answers instead of confident hallucinations.
Tool use: Perhaps one of its greatest strengths, GPT-5 is really great at tool use. Latent Space wrote a great review of GPT-5, comparing us to being at the stone age of AI for the ability to use tools effectively:

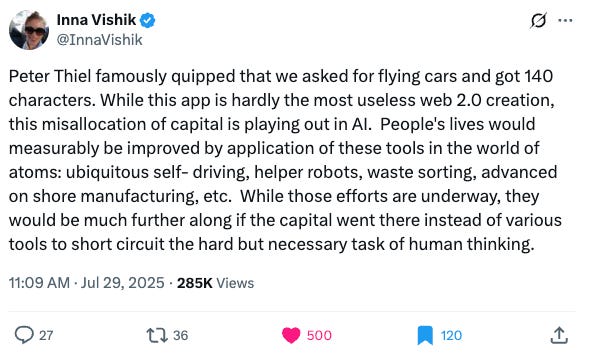
Is it actually smart? Our friends over at AI Supremacy share my exact thoughts, “just good enough,” snip from their excellent write-up below:
Strategic implications: The unified router is as much a business move as a technical one. I think, perhaps, this is the real story of the release. The smart router lets OpenAI dynamically manage inference costs, prevent overuse of heavy models, and lock in the default experience. For enterprises, it simplifies model selection but removes transparency over which model is running – a shift in power toward the platform.
Competitively, GPT‑5’s pricing ($1.25/million input tokens, $10/million output) undercuts Anthropic’s Sonnet 4 and forces pressure on rivals to respond, especially in the coding segment where Anthropic has gained share. I annotated below a section from John Hwang’s excellent post on GPT-5 and its strategic implications:

Other misc GPT-5 observations in the wild
On the agentic abilities:
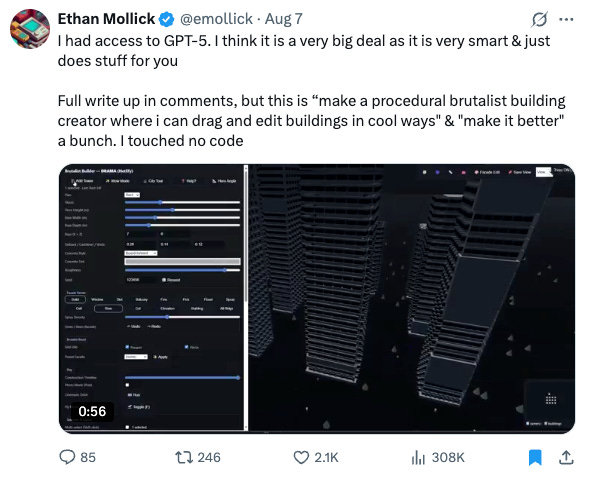
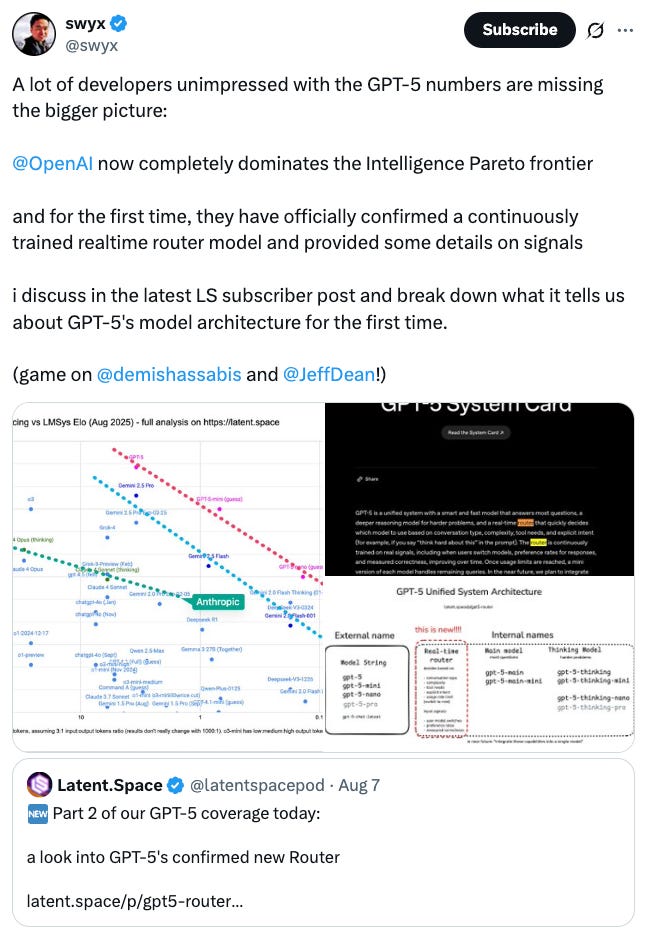
On the Intelligence Pareto frontier:
From Aaron Levie, CEO of Box, who got an early preview of GPT-5 and has been testing it for weeks.
His full post is too long to publish on the blog, read it in full here, below for a snip:

From Allie Miller, an influential voice in AI business:
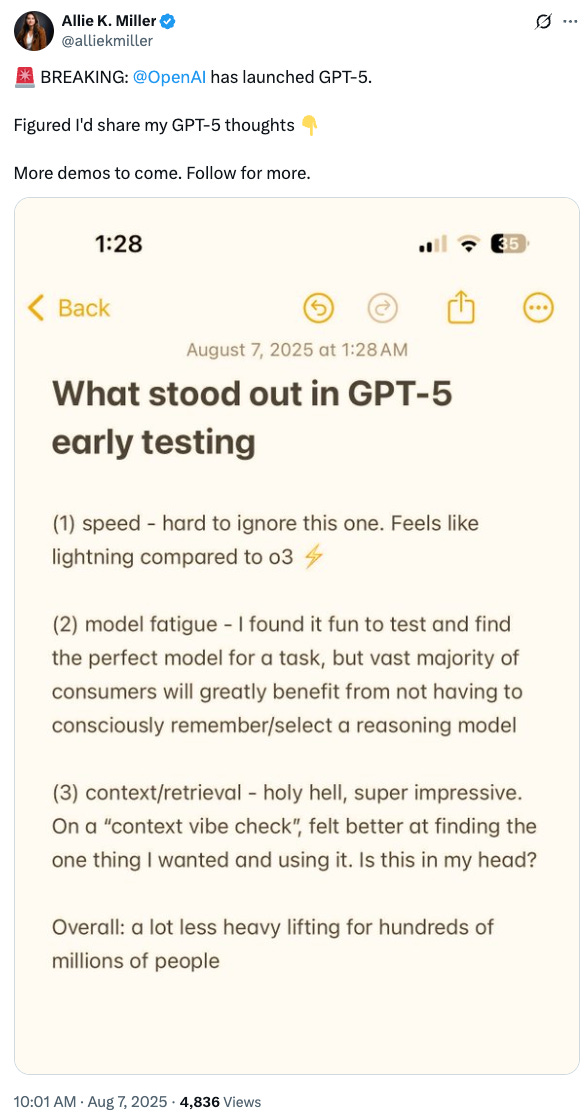
On the launch reflecting the desire to go full-on consumer, an interesting and provocative observation:
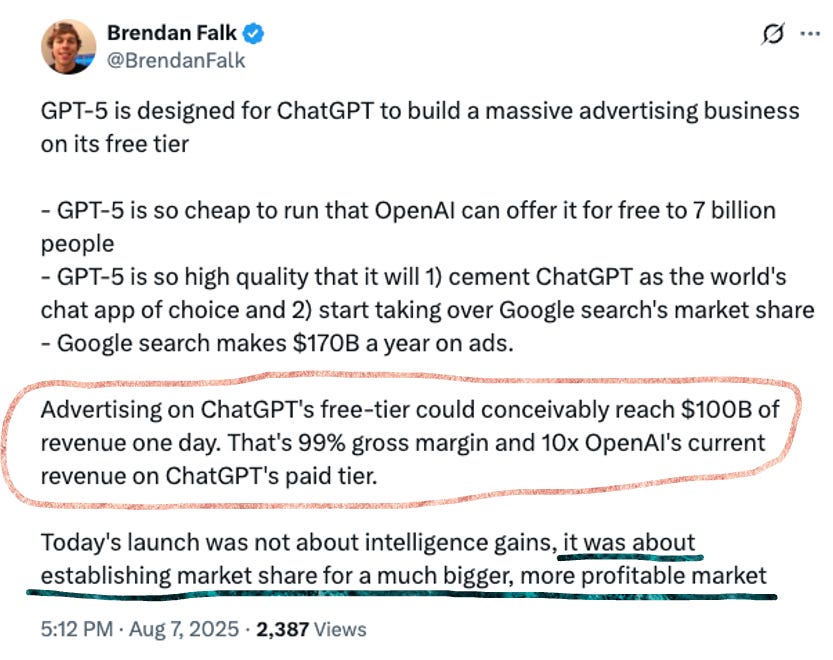
Consumers who were already avidly using ChatGPT bemoan the lack of choice:
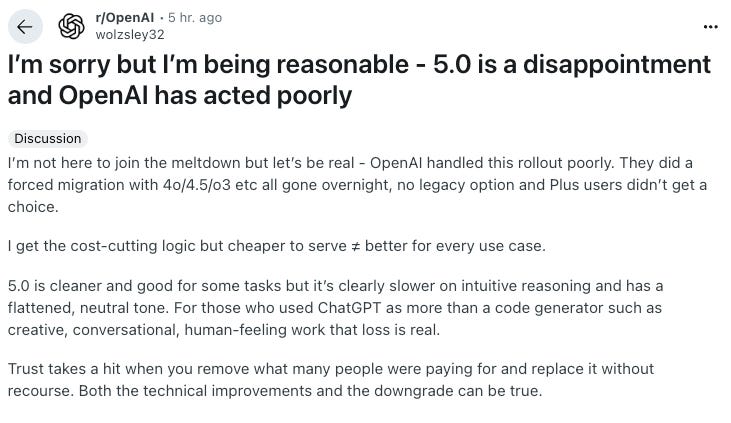
And also bemoan the feeling of incrementalism (note below Sam’s post and subsequent comment):
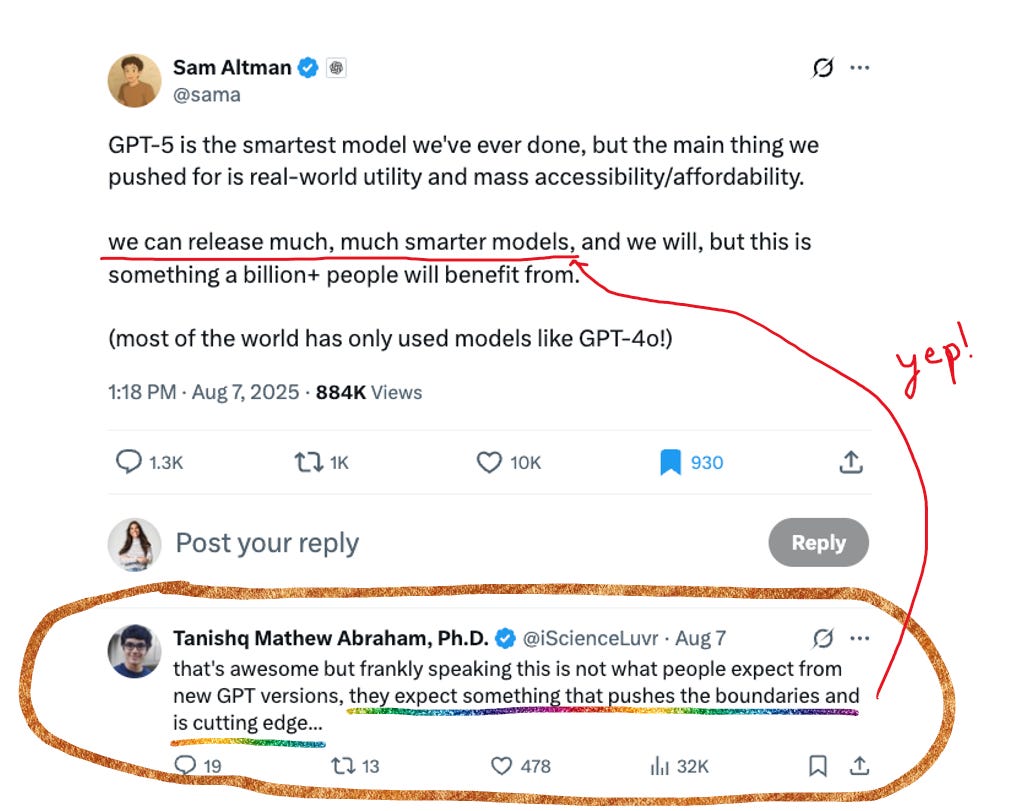
A 24-hours-later update from Sam following the launch:
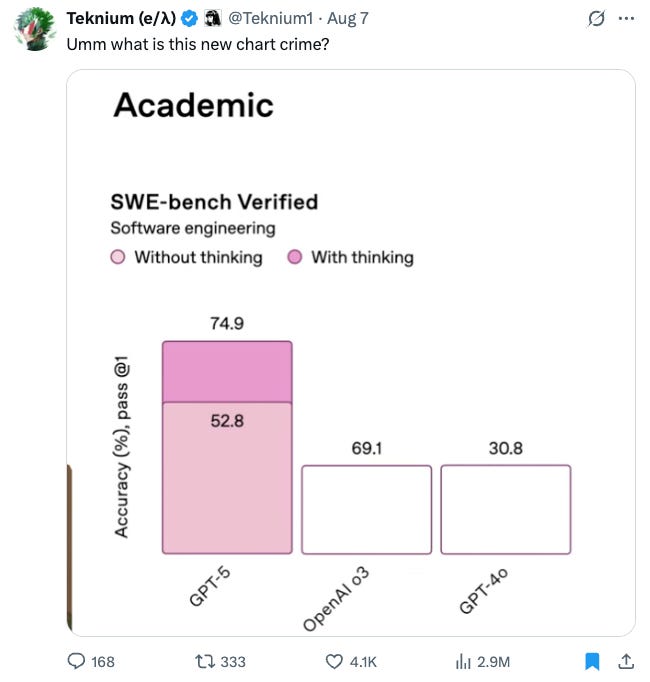
Lastly, I will never forget the ridiculousness of this chart crime from the livestream video:
More to come as it has only been a day and I’m sure we will have more to chat about as GPT-5 permeates in the wild.
But lest you think the world this week revolved solely around GPT-5, fear not! This week saw plenty other great releases, too.
I’ll now spend some time being nice about OpenAI, because their much-awaited gpt-oss was actually a pretty awesome release. Guillermo Rauch, CEO of Vercel, said it well:
gpt‑oss: what OpenAI actually opened (and why it matters)
We’re back in ‘Murica, baby! 🇺🇸
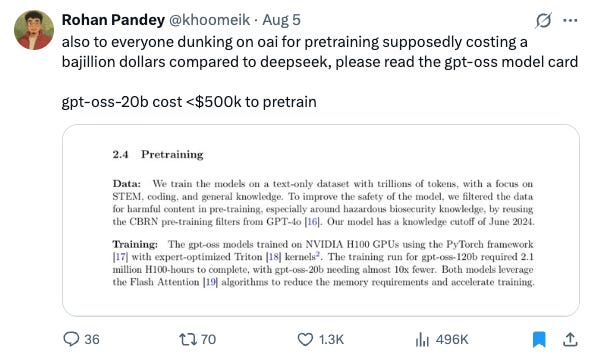
Release & license: On Aug 5, OpenAI released gpt‑oss‑120b and gpt‑oss‑20b under Apache 2.0, with a full model card and reference code. This is the first open‑weight release from OpenAI since GPT‑2.
Architecture & footprint: Both are Mixture‑of‑Experts (MOE baby!!!) Transformers. The 120b checkpoint activates ~5.1B parameters per token and can run on a single 80GB GPU; the 20b activates ~3.6B and can run on hardware with ~16GB memory. Context length is ~131k tokens. The repo ships an optimized Triton MoE kernel and memory tweaks for attention.
Where you can actually run it: Day‑one integrations landed across clouds and runtimes: AWS Bedrock & SageMaker JumpStart, Azure AI Foundry / Windows AI, NVIDIA NIM, Hugging Face Inference Providers, and desktop‑friendly stacks like Ollama and LM Studio. The point is less hobbyist tinkering and more: minimal friction to slot it into real deployments.
Performance bracket: OpenAI positions 120b in the neighborhood of o4‑mini on reasoning/coding/math evaluations; 20b tracks closer to o3‑mini. The model card and early coverage call out long‑context reliability and strong tool‑use, but also note it’s text‑only.
Strategic context: Releasing usable open weights does three things at once: (1) absorbs developer energy that might have flowed to Llama/Qwen/DeepSeek; (2) gives procurement a credible local option without leaving OpenAI’s ecosystem; (3) builds a partner chorus across clouds/hardware that amplifies distribution.
It also meaningfully shifts the competitive landscape in open source land, and beyond.
From The Deep View regarding OpenAI vs. Meta:

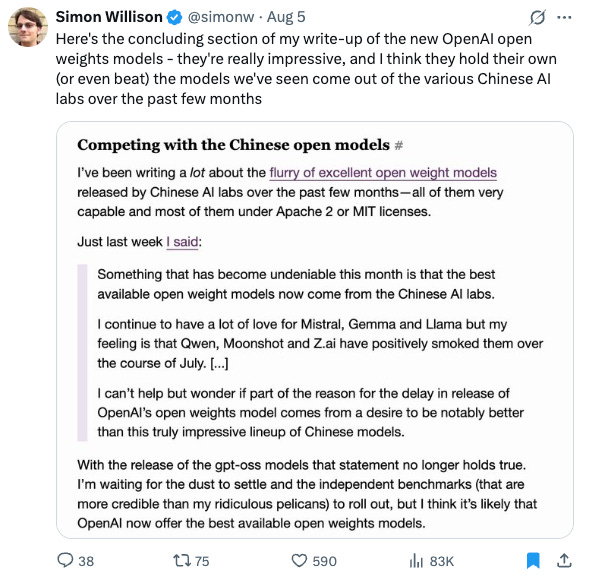
And also in geopolitics! From Simon Willison, on the fear that China would remain dominant in open weights:
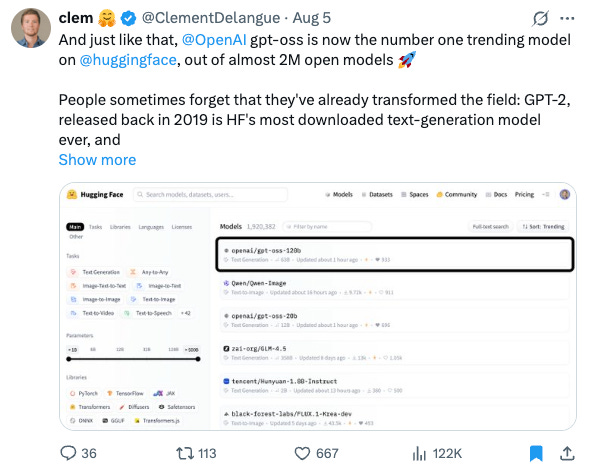
And lots of love, as expected, from open source AI’s number 1 champion, Clem from Hugging Face:
Ok, enough about OpenAI. Now on to our other two players, Anthropic and Google.
Claude Opus 4.1: incremental upgrade to Opus 4
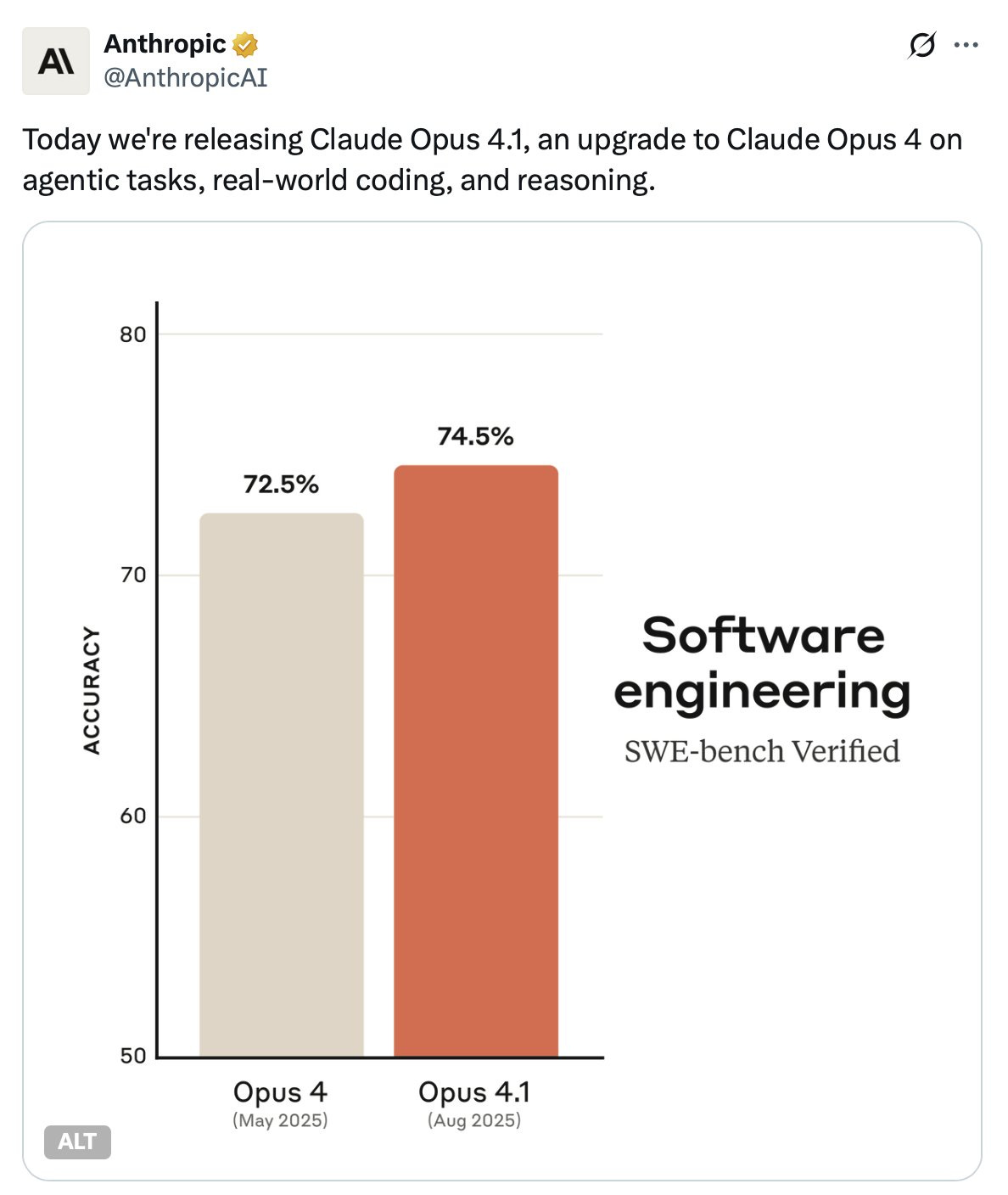
Release & headline number: It was an incremental release to the very recently released Opus 4. Anthropic’s Opus 4.1 posts 74.5% on SWE‑bench Verified and emphasizes steadier behavior on multi‑step work.
What’s actually better: Beyond the headline, Anthropic highlights tighter multi‑file refactors and fewer extraneous edits. Independent summaries also note small but real gains on terminal‑style tasks and multilingual reasoning. Opus 4.1 supports long outputs (useful for bigger diffs) and is also available in Claude Code.
Competitive prism: On the canonical coding benchmark, GPT‑5 claims 74.9% vs Opus 4.1’s 74.5% – basically a draw.
What to watch: I think pricing is the real story here especially on the same week as the GPT-5 launch; 4.1 feels expensive:

Let us now see how Anthropic will respond! Give me Opus 5, kings.
Genie 3: the world becomes the training ground
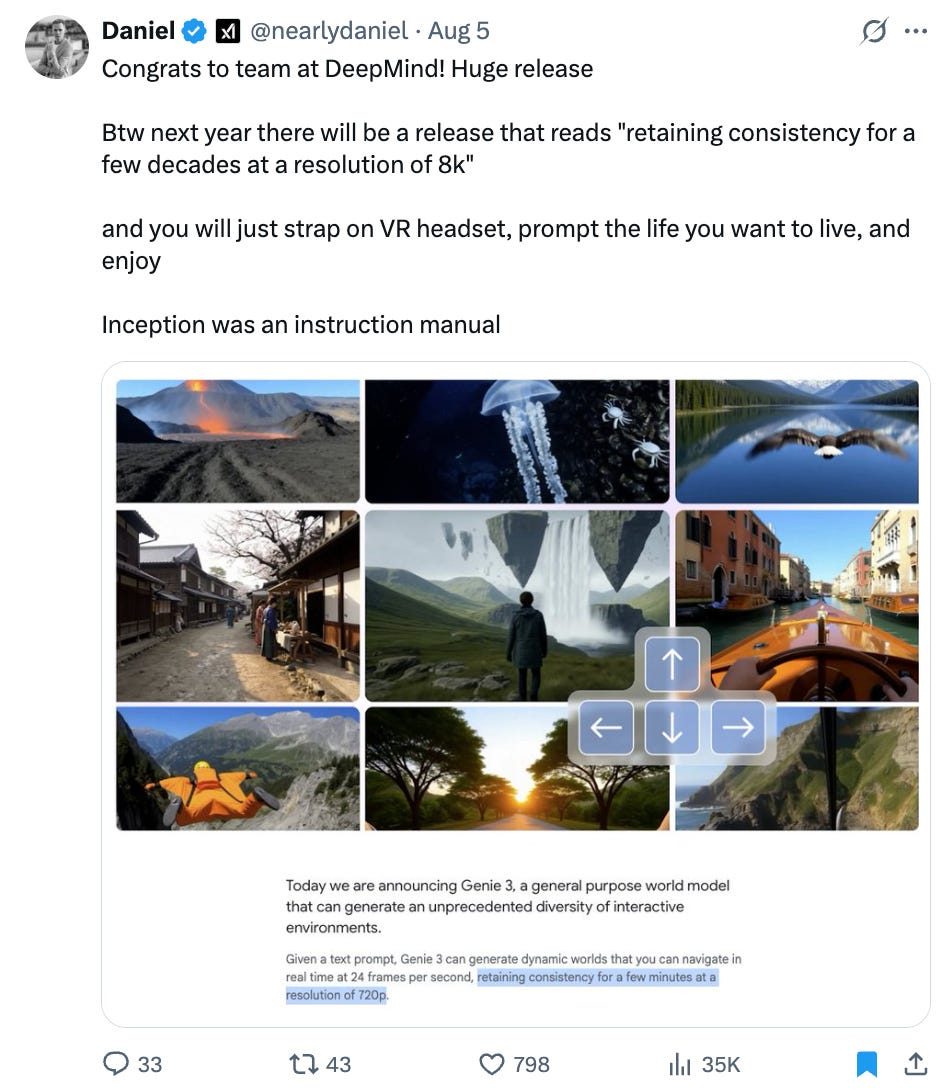
What is it: Google DeepMind’s Genie 3 is a general-purpose world model that generates interactive 3D environments from text or image prompts – rendered at 720p, 24fps, with persistent memory of your actions for minutes at a time, not seconds. It’s “not specific to any environment,” and users can actually explore and manipulate these worlds in real-time.
What’s new: Past world models faded after a few frames, but Genie 3 keeps the world consistent long enough to train agents meaningfully (or prototype spatial logic) not just watch it collapse on reset. According to Jack Parker-Holde from DeepMind, this kind of simulation capability is a vital stepping stone toward embodied AGI.
Use cases on the table: They include training AI agents in complex, dynamically changing scenarios, and building immersive educational or discovery tools. In demos, agents like SIMA can be guided to reach objectives (e.g., walk to a red forklift) within Genie-generated environments.
Limitations (and realism check): Memory lasts just a few minutes, physical realism is still imperfect, and steering precise behavior remains a hard problem. Reviewers caution that despite the jaw-dropping visuals, the tech today is more art demo than production-ready simulation.
My takeaway: Genie 3 is a step towards creating environments that behave consistently enough to be acted upon, by humans or models. That opens a new class of AI training pipelines that aren’t just prompt → response, but agent → environment → learn. While there doesn’t seem like there is much practical to do with it yet, I’m looking forward to what future releases have in store in world model land.
I’ll say this: Genie 3 actually points toward the kind of thinking I want to see more of – building fundamentally new capabilities rather than optimizing existing ones. But it's still early-stage research, not a product that changes how we work or solve problems today.
Parting thoughts
What would actually get me excited? An AI that can maintain coherent reasoning across weeks, not just tokens. Systems that can genuinely collaborate with human experts to solve novel problems rather than optimizing existing workflows. Models that surprise us with emergent capabilities we didn't train for, rather than just getting better at what we already know they can do. Show me something that makes me believe we're building toward the Machines of Loving Grace instead of just Machines of Loving Revenue.
Until then, we're getting very good at building faster horses while the world waits for someone to invent the car.

Really balanced take, Jessica. It doesn't feel like a seismic shift. I feel that GPT-5 has become a poorer writer, and while the "routing" idea is well-intentioned, it doesn't always get the choice of model right IMO. Have had to retry a few prompts more than once. Plus, I don't get this notion of one-shotting apps. Outside of the benefits of quick prototyping, it promotes a culture of shipping potentially broken software. I wonder if I'm being really spoilt for saying all this given how amazing it is to speak your thoughts into life.