
Google Won’t Stop Shipping
Gemini 3 Flash, OpenAI Image Gen 1.5 & GPT-5.2-Codex, and suddenly everyone has Skills 🧑🍳

Last week OpenAI answered “code red” with GPT-5.2. This week Google said “that’s cute” and released Gemini 3 Flash — frontier-grade reasoning at Flash pricing. We’re talking $0.50 per million input tokens.

OpenAI wasn’t sitting still though — GPT-5.2-Codex came out (agentic coding focus), and more notably, they released GPT Image 1.5, which just claimed the #1 spot on LM Arena. The image wars are heating up again!
But here’s what really caught my eye this week. Some sleuthers were poking around ChatGPT’s code interpreter and noticed something interesting: there’s now a /home/oai/skills folder. Skills! As in, the thing Anthropic has been doing for months! The folder covers spreadsheets, docx, PDFs... sound familiar?
The great convergence is upon us, friends. Everyone’s copying everyone. Google adopted Anthropic’s MCP into their cloud. OpenAI adopted Anthropic’s Skills. Anthropic is testing new agentic modes that look suspiciously like what everyone else is building. It’s like watching fashion trends — give it six months and everyone’s wearing the same thing.
Speaking of convergence, let’s talk about the OTHER thing OpenAI is chasing: Amazon’s checkbook (and a $830B valuation?!). More on that below.
Let’s get into it:
📋 This Week’s Cheat Sheet:
Gemini 3 Flash ships — Frontier benchmarks at Flash latency. $0.50/$3.00 per 1M tokens. Already live in Cursor, VS Code, Perplexity, Ollama. Google is moving FAST.
OpenAI in talks for $10B from Amazon (and perhaps a $750B valuation) — The capital arms race continues!
OpenAI GPT Image 1.5 — LMArena says it’s now the #1 image model. My vibes say it’s on par with Nano Banana Pro. Not a leap over what’s already out there, though certainly a leap from OpenAI’s previous image gen model.
GPT-5.2-Codex ships — OpenAI's most advanced agentic coding model. SOTA on SWE-Bench Pro (56.4%) and Terminal-Bench 2.0. Context compaction for long-horizon work, plus a new invite-only program for cybersecurity pros.
Google Deep Research gets an API — The new Interactions API lets devs build with the research agent. Plus MCP is now baked into Google Cloud.
ChatGPT adopts Skills — The Anthropic playbook spreads. Imitation, flattery, etc.
Anthropic testing Agentic Tasks Mode — New interface with toggle between chat and agent modes. Screenshots floating around.
NVIDIA Nemotron 3 — Actually fully open. Weights, data, training recipes. All of it. Strategic hedge incoming.
OpenAI kills the equity cliff — No more 6-month vesting wait. $6B in stock comp this year. The talent wars are expensive!
⚡ Gemini 3 Flash: Frontier Intelligence, Flash Prices
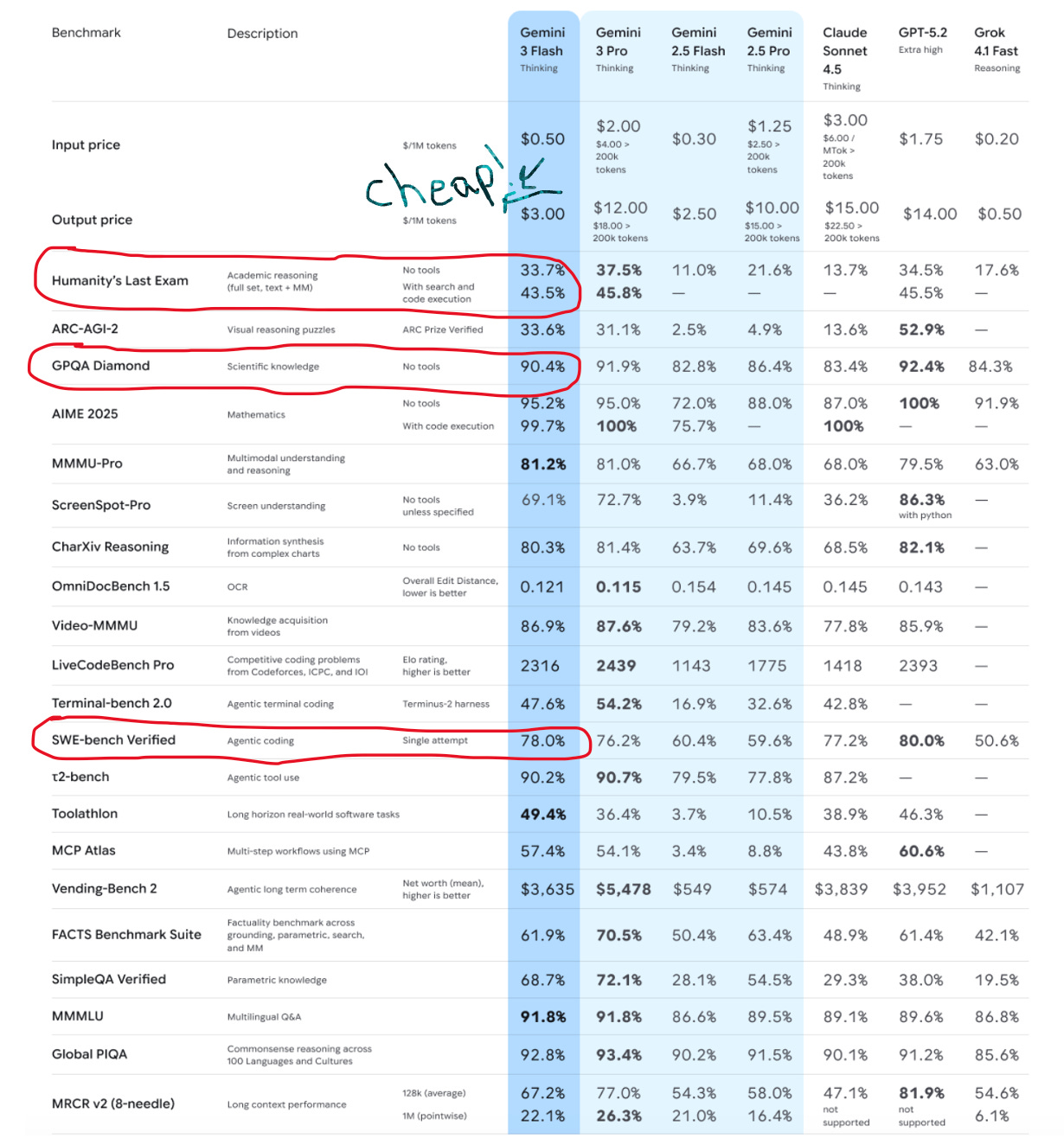
Google just released Gemini 3 Flash, and the positioning is chef’s kiss 😙🤌: “Pro-grade reasoning at Flash speed.” It’s now the default in the Gemini app and Search AI Mode, and it’s available to devs via Google AI Studio, Vertex AI, and basically everywhere else.
The specs that matter:
Pricing: $0.50 per 1M input tokens, $3.00 per 1M output. That’s... really cheap for frontier-ish performance.
Context: Up to 1M tokens
Benchmarks: Beats or matches Gemini 3 Pro on ARC-AGI-2 and SWE-bench Verified in some configs. Rivals GPT-5.2 in certain agentic/coding settings.
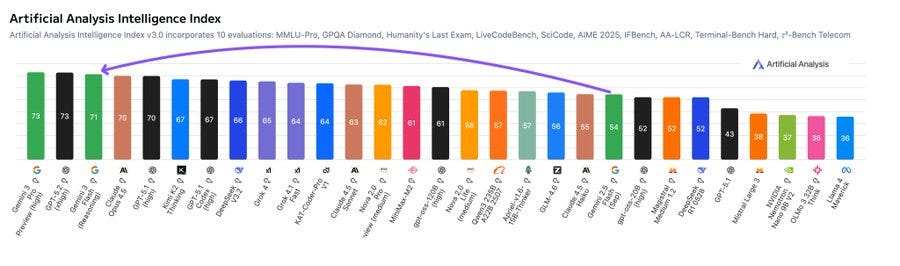
The early results from Artificial Analysis are really strong, assessing it as “the most intelligent model for its price range” — high knowledge/reasoning scores, second place on MMMU-Pro, and of course strong pareto position on price/performance. BUT (and this is a big but!) they flagged 91% hallucination on their AA-Omniscience benchmark. So... maybe don’t trust it with your medical records just yet? 🙃
The thinking levels are clever; flash exposes three thinking modes: low, med, and high.
Where it’s already live: Cursor, VS Code, Perplexity (in Pro/Max), Ollama Cloud, LlamaIndex. The integration velocity is impressive. Google is clearly shipping to devs first this time.
The bigger picture: Google shipped Gemini 3 Flash the same day they launched an upgraded Deep Research Agent with a developer API (more on that in bits & bobs section), AND they integrated MCP into Google Cloud. Three major developer-facing releases in one week. This is not the sleepy Google of 2023. Someone over there is highly caffeinated.

🎨 OpenAI Image 1.5: Back on Top
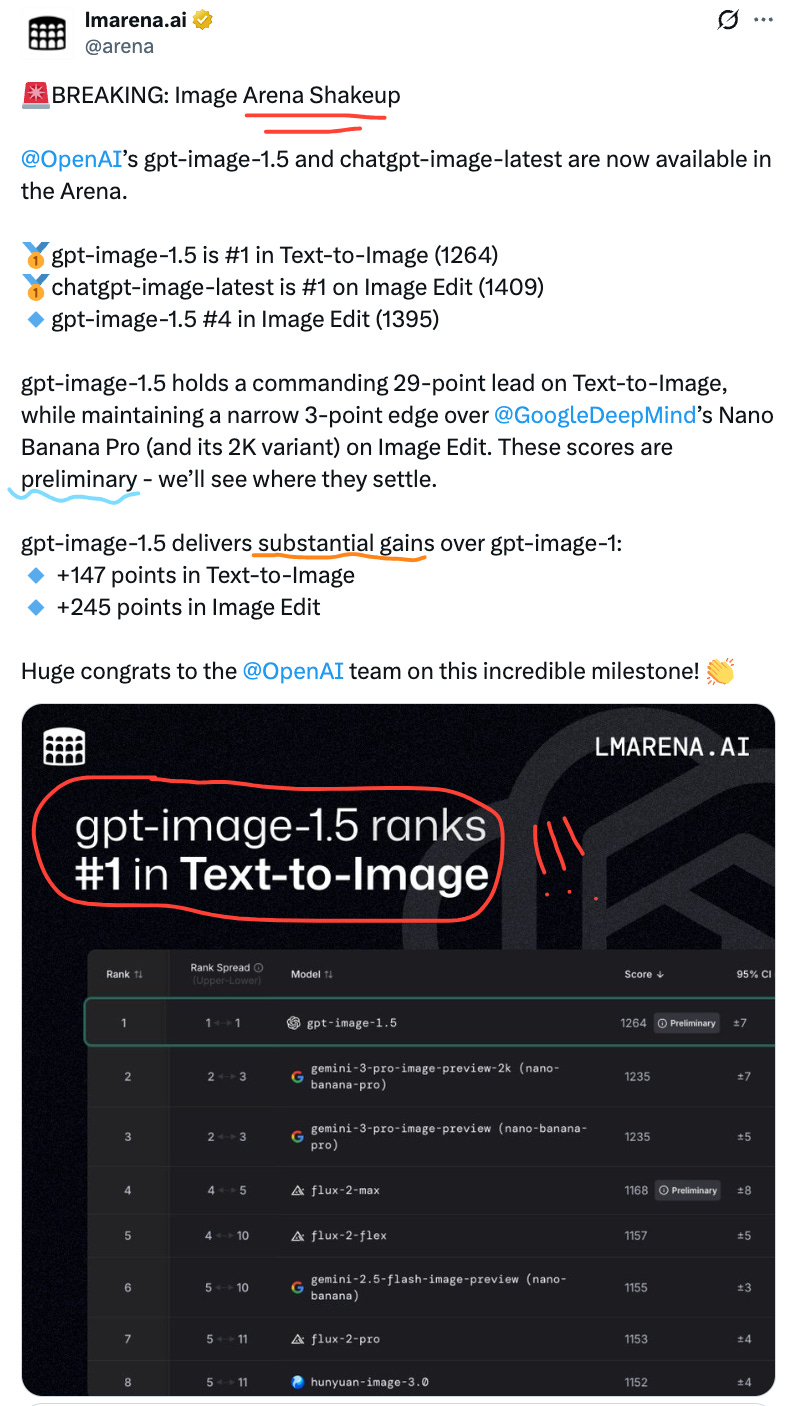
OpenAI released Image 1.5 this week, and it just claimed the #1 spot on LM Arena’s image generation leaderboard. And Sam kindly graced us with his AI-generated abs, because at this point of the year, why not!!

The release is a significant upgrade over previous ChatGPT image capabilities — better coherence, more consistent style adherence, and noticeably improved text rendering (always the Achilles’ heel of image gen). For anyone who’s been frustrated with ChatGPT’s image output compared to Midjourney or the dedicated tools, this is the response.
The honest vibe check though: It’s a clear “wow” compared to where ChatGPT images were six months ago. It’s less of a “wow” compared to what’s already out there from the dedicated image gen players. The Ghibli moment this is not. More like... catching up to the frontier rather than redefining it.
But #1 on LM Arena is #1 on LM Arena. And for the millions of ChatGPT users who want image gen without switching tools, this matters. The “best and convenient” market is enormous.
🧑💻 GPT-5.2-Codex: OpenAI’s Coding Counterpunch
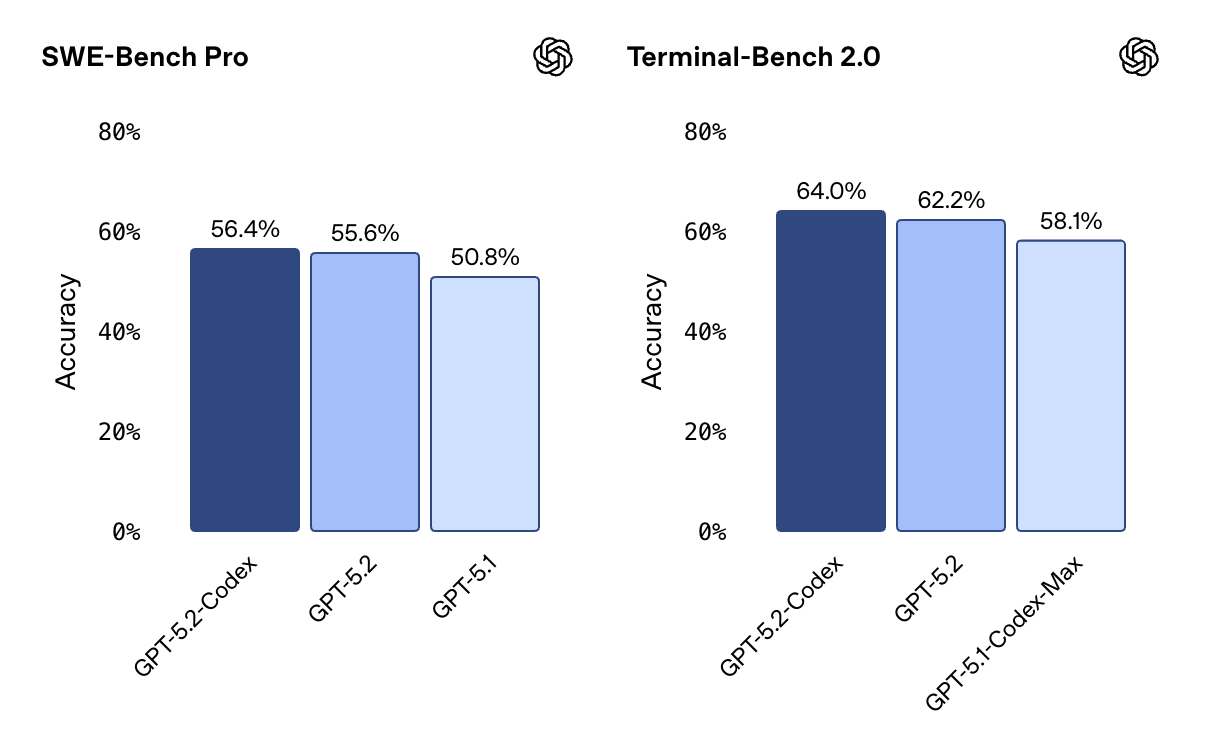
OpenAI also released GPT-5.2-Codex this week — their most advanced agentic coding model yet, and yet another shot at Anthropic’s coding crown.
What’s new:
Context compaction — the model can work on long-horizon tasks without losing context. Big refactors, code migrations, multi-hour sessions — it stays coherent.
SOTA benchmarks — 56.4% on SWE-Bench Pro, 64.0% on Terminal-Bench 2.0
Better vision — can interpret screenshots, technical diagrams, and UI mocks, then translate them into functional prototypes
Windows support — finally more reliable in native Windows environments
Cybersecurity capabilities — significantly stronger than previous models. A researcher using the previous version (GPT-5.1-Codex-Max) found and responsibly disclosed a vulnerability in React just last week.
The cybersecurity angle is interesting. OpenAI is launching an invite-only trusted access program for vetted security professionals — essentially a more permissive version of the model for defensive work. They’re clearly thinking about dual-use risks here.
💰 OpenAI’s Amazon Courtship

The Information reported that OpenAI is in talks to raise at least $10 billion from Amazon. The deal would involve using Amazon’s AI chips — presumably their Trainium instances.
Let me do some quick math here. In the past few months, OpenAI has:
Raised from SoftBank
Landed a $1B strategic investment from Disney
And now potentially $10B from Amazon?
That’s a LOT of capital formation happening while they’re simultaneously in “code red” mode trying to catch up to Gemini. The narrative writes itself: OpenAI is building a war chest for the compute arms race because they know the next few years are going to be expensive.

The Amazon angle is interesting though. Microsoft is OpenAI’s primary cloud partner and investor. Amazon is Microsoft’s biggest cloud competitor. Is this about OpenAI diversifying their compute dependencies? Is it more pointed – Hedging against Microsoft having too much leverage? (Which was definitely a theme this year with their rift and sort-of breakup). Or is it really way less specific and really more about just taking money from whoever will write checks?
(Probably a mix of them all!)
And it sounds like Amazon is not the only one being courted - reports say OpenAI is holding talks in the market to raise $100B at a $830B valuation.
🧑🍳 The Great Copycat Convention

Okay, can we talk about how everyone is just... implementing the same patterns now?!
Exhibit A: ChatGPT now has Skills. Thank you Simon Willison for the writeup and Elias Judin for the discovery. Anthropic released Skills a while back — basically folders with markdown files and code scripts that teach the model to do something repeatedly. Simple but powerful. Well, ChatGPT’s code interpreter now has /home/oai/skills covering spreadsheets, docx, and PDFs. The Anthropic playbook spreads! (Presumably options to add custom skills coming soon.)
Exhibit B: Google went all-in on MCP. Anthropic’s Model Context Protocol is now integrated into Google Cloud, letting AI models natively access Maps, BigQuery, Compute Engine, and Kubernetes without custom interfaces. Remember when MCP was “Anthropic’s thing”? Now it has 97M monthly SDK downloads and Google is shipping managed MCP servers.
Exhibit C: Everyone’s building agent modes. Anthropic is testing a new Agentic Tasks interface with toggles between chat and agent modes, plus specialized modes for research, analysis, writing, and building. Meanwhile, Google’s Deep Research Agent just got a developer API (the new Interactions API). And OpenAI has been shipping agent-y features into ChatGPT for months.
The convergence is real! Honestly I think it’s fine. Maybe even good? Actually… great!!! The best patterns should spread. Competition on implementation is healthy. We’re moving from “who invented this” to “who executes it best.” The consumer, i.e. you and me, are the real winners!
Also notable: Tinker by Thinking Machines is now open for everyone — lets researchers fine-tune and experiment with open models easily. Launched with Kimi K2 support, image-based fine-tuning, OpenAI API-compatible inference. The tooling layer is getting really good.
🟢 NVIDIA’s Strategic Hedge
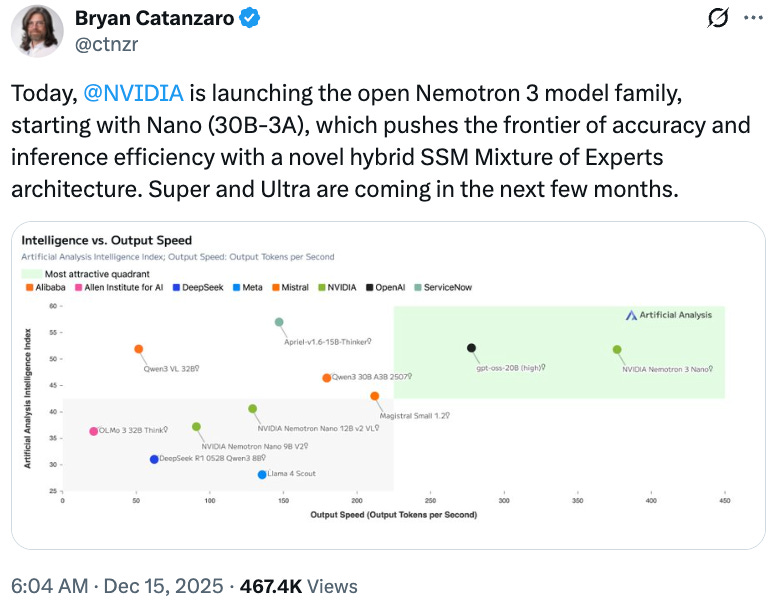
NVIDIA released Nemotron 3 this week, and what’s interesting here isn’t the benchmarks (they’re competitive with Qwen3, nothing earth-shattering). What’s interesting is HOW open it is.
From the paper:
“We will openly release the model weights, pre- and post-training software, recipes, and all data for which we hold redistribution rights.”
Actually open! Weights AND data AND training recipes. This is one of the most complete open releases to date — new architecture (hybrid SSM/MoE), transparent training pipeline, everything.
The specs:
Nemotron 3 Nano: 30B parameters, 3B active (shipping now)
Nemotron 3 Super: 100B (coming early 2026)
Nemotron 3 Ultra: 500B (coming early 2026)
Why is NVIDIA doing this? I have a theory! 🕵️♀️
NVIDIA’s biggest customers are OpenAI, Google, Anthropic, Microsoft, and Meta. And ALL of them are increasingly building their own chips instead of buying NVIDIA. Google has TPUs. Amazon has Trainium. Microsoft wants to work on the next gen of Maia 100. Meta has their custom silicon efforts. Even OpenAI is working on chips (with Broadcom! Deep cut!).
So what do you do when your customers are trying to become your competitors? You commoditize the layer above you. If NVIDIA can make frontier-quality models genuinely open and easy to run, they’re lowering the switching costs for everyone EXCEPT the hyperscalers — and potentially building goodwill with the long tail of enterprises who don’t want to be locked into any one model provider.

Smart hedge! Whether the models are actually good enough to matter is a different question.
🔬 Bits & Bobs
🤖 Models & Products
Google Deep Research API — The Interactions API now gives developers access to the autonomous research agent. It’s built on Gemini 3 Pro and does the multi-minute deep research thing that everyone was obsessed with a few months ago. The play here is obvious: deep research as background capability, like how RAG is everywhere but you don’t think about it.
Google Disco — Turns browser tabs into mini-apps for research, planning, and prototyping. Interesting form factor play.
Meta SAM Audio — Meta released the first unified multimodal model for audio separation. You can isolate sounds using text prompts ("remove the background music"), visual cues (point at the person speaking), or temporal markers (extract audio from 0:30-0:45). State-of-the-art performance. The multimodal input angle is clever — much more intuitive than traditional audio editing.
💼 Business Moves
OpenAI ends equity vesting cliff — No more 6-month wait for new employees. The company expects to spend about $6B (!!!) on stock-based pay this year — nearly half of projected revenue. Man oh man. The talent wars are brutal.
🔮 Worth Reading
Alberto Romero’s 20 Predictions for AI in 2026 — Always a thoughtful read from the Algorithmic Bridge. Some spicy takes in there.
🔮 So What Does This All Mean?
1. Google’s shipping velocity is no joke.
Gemini 3 Flash + Deep Research API + MCP integration + Disco — all in one week. This is the opposite of the old Google that sat on good research (ahem, Attention is all You Need) for years. Someone clearly got the memo that speed matters. And they’re going developer-first this time, which is smart. Win the devs, win the ecosystem.
The question is whether they can maintain this pace AND quality. The 91% hallucination rate on AA-Omniscience is a real caveat. Fast and good is hard. Fast and cheap and good is really hard.
2. The agent infrastructure layer is standardizing faster than expected.
MCP has 97M monthly SDK downloads. Google is shipping managed MCP servers. Last week, Anthropic, OpenAI, Google, and Microsoft formed the Agentic AI Foundation through the Linux Foundation. Skills are spreading from Anthropic to OpenAI.
Six months ago, everyone had their own bespoke way of doing tool calling and agent orchestration. Now there’s genuine convergence on patterns and protocols. This is good for anyone building agents — and probably bad for anyone hoping to win on proprietary infrastructure alone.
3. OpenAI is playing a different game right now.
GPT-5.2 shipped. Disney wrote a $1B check. Amazon might write a $10B check. Three public company CEOs now run their business operations. The equity cliff is gone to help with talent retention.
Even if last week’s narrative may have been “catch up to Gemini on model quality,” I think we’re very quickly pointing ourselves towards “prepare for an IPO or massive expansion.” Capital formation, enterprise positioning, management bench building — these are the moves you make when you’re thinking about the next (grand) chapter, not just the next model release.
Whether that’s the right priority while Google is shipping this aggressively... I genuinely don’t know! But it’s a bet. You gotta make ‘em.

🫡 ‘til next week friends!
—Jess
Nothing I’ve tried beats Nano Banana Pro so far. The consistency alone changed how I work. Thanks for the great summary!🩷🦩
Great summary!! Thanks for sharing!!