
OpenAI Hits the Panic Button
Three years ago Google declared "code red" over ChatGPT. Now it's Sam's turn.


It’s never over ‘til it’s over – three years ago, Google declared “code red” when ChatGPT launched and ate their lunch. This week - how the tables have turned!

Sam Altman told employees OpenAI is in “code red” mode. Gemini keeps racking up converts. And a new 100 trillion token study just revealed that reasoning models now account for half of all inference.
📋 This Week’s Pulse Check:
OpenAI freezes projects, fast-tracks “Garlic” model to catch Gemini 3
Anthropic preps for IPO, raising at $300B+, signs $200M Snowflake deal
Claude Opus 4.5 reclaims coding crown with 80.9% SWE-bench
Reasoning models hit 50% of all inference (up from near-zero a year ago)
Let’s get into it:
🚨 OpenAI’s Code Red
The timing here is brutal. Just as Gemini 3 is winning hearts and minds, OpenAI’s internal alarm bells are ringing. From Sam:

What’s happening:
Altman declared “code red” internally, freezing non-essential projects
Shopping features, health agents, advertising experiments, personal assistant “Pulse” – all paused
Daily check-ins now mandatory; employees being shuffled between teams
Fast-tracking a new model codenamed “Garlic” (also one called “Shallotpeat” – someone loves alliums lol 🧄)
Chief Research Officer Mark Chen briefed employees that Garlic is showing strong results on internal coding and reasoning benchmarks. The key breakthrough: solving pretraining efficiency issues that plagued GPT-4.5, allowing smaller models to pack more capability. From The Information:
“Chen said OpenAI is looking to release a version of Garlic as soon as possible, which we think means people shouldn’t be surprised to see GPT-5.2 or GPT-5.5 release by early next year.”
The wider context makes this spicier. Michael Spencer’s recent breakdown paints a rough picture: a “disastrous” GPT-5 launch, Sora flopping, hardware delays, $12 billion annual cash burn, and partners sitting on ~$100 billion in debt for speculative infrastructure. Meanwhile Google is vertically integrated (TPUs, infrastructure, distribution) and ChatGPT’s lead is shrinking – 800M weekly users vs. Gemini’s 650M monthly. Still a big gap, but Google is closing fast.
There was a Marc Benioff tweet that must’ve stung, because it’s a signal of times to come. When a Fortune 500 CEO publicly switches (AI) teams, people notice:
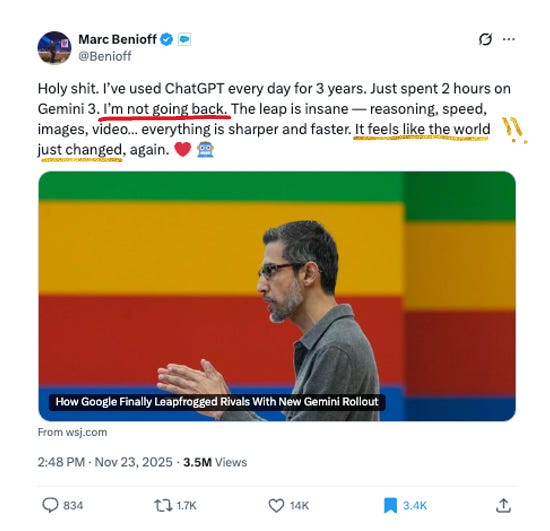
But let’s all take a breather here — no “it’s so over” in this blog, thank you very much. One thing we have learned in the past three years is to never discount OpenAI. I’ll never forget everyone’s surprise when OpenAI was the first to truly break through on images (remember Ghibli mania??!) - it wasn’t expected. They are still synonymous with AI for most of the population - and I look forward to see what all those allium-named models bring. Hopefully, some better naming, too 😂.
🏆 Claude Opus 4.5: The Comeback

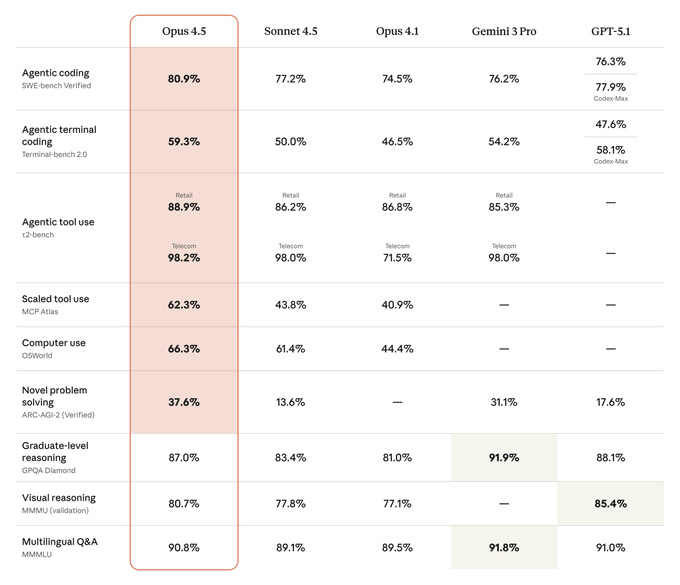
Buttt, again - OpenAI is not the one crushing it right now. Anthropic released Claude Opus 4.5 on November 24th and reclaimed the coding crown.
The numbers:
80.9% on SWE-bench Verified (vs. GPT-5.1 at 76.3%, Gemini 3 Pro at 76.2%)
66.3% on OSWorld (computer use)
Scored higher than any human candidate on Anthropic’s internal engineering take-home test
15% improvement over Sonnet 4.5 on Terminal Bench
What’s different: This is Anthropic’s first flagship Opus that actually makes sense to use daily. Pricing dropped to $5/$25 per million tokens. Long conversations no longer hit a wall – Claude automatically compresses earlier context. And they removed Opus-specific usage caps for Max subscribers.
The real story: Opus 4.5 handles ambiguity and reasons through tradeoffs without hand-holding. Testers said tasks that were near-impossible for Sonnet 4.5 are now within reach. For professional software engineering and complex agentic workflows, this is the new default.
I can personally attest that I cancelled my $200/mo subscription to ChatGPT and am now paying for Anthropic’s $200/mo subscription instead. N of 1, but there it is!
📈 Anthropic’s Orthogonal Bet Is Paying Off
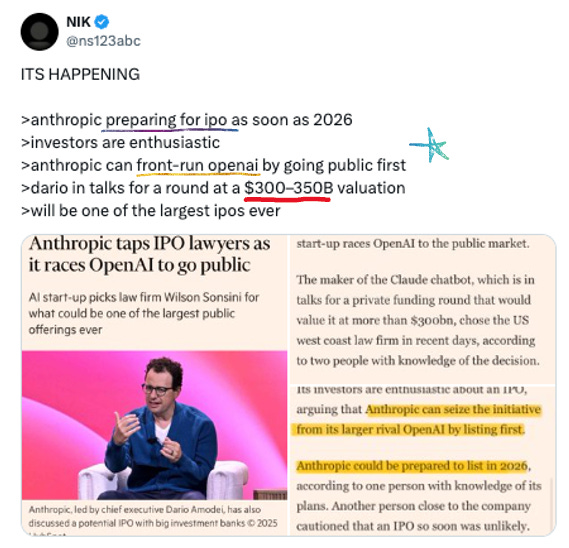
Continuing on the Anthropic hype train here for a moment. While OpenAI scrambles this week, Anthropic is doing something rather more interesting: preparing for an IPO! The public markets can be much harsher judges of the AI hype - I am looking forward to seeing retail reaction to the Anthropic offering. Going first also helps them be better known to consumers, given that today OpenAI/ChatGPT is still very much the best known AI product. It’s a fascinating capital + marketing strategy.
Current status:
Hired Wilson Sonsini (took Google, LinkedIn, Lyft public) for IPO prep
Announced a commitment of $15B in investment from Microsoft + Nvidia
Reportedly raising a (private) funding round that would value it >$300B
Just signed a $200M multi-year deal with Snowflake
Dario telling investors annualized revenue could hit $26B next year
What’s notable is how they got here. Anthropic’s strategy was deliberately orthogonal to OpenAI’s: enterprise-focused rather than consumer-obsessed, safety-forward in messaging, less splashy product launches but steady capability improvements. They didn’t try to win the ChatGPT popularity contest. They went after the customers who write big checks and need reliability.
That bet is looking smart. 300,000+ business customers. Considered the coding leader by many enterprise teams. Thousands of Snowflake customers already processing trillions (!!!) of Claude tokens per month. And now potentially racing OpenAI to the public markets.
📊 What 100 Trillion Tokens Tell Us
OpenRouter just released a massive empirical study of real-world LLM usage. Some findings surprised me.
The headlines:
Below for the charts I found most interesting:
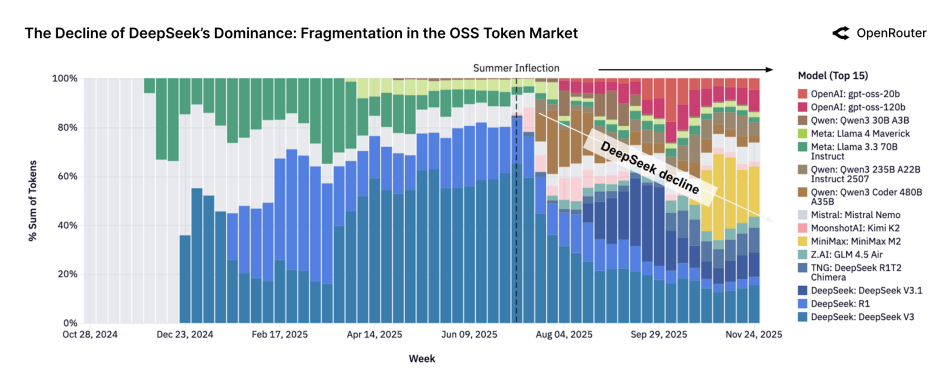
The fragmentation of the OSS market
Grok usage stronger than you’d think!

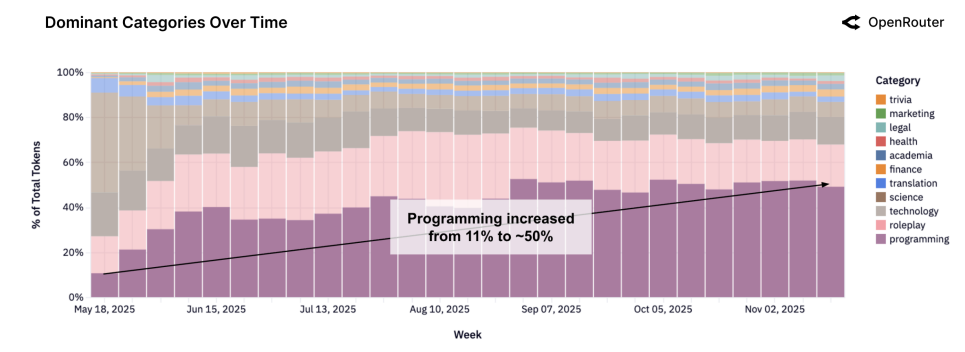
It’s all about coding
Lastly, the insight that really matters for AI builders: The report identifies a “Cinderella Glass Slipper” retention effect. Early users who find perfect model-market fit stick around far longer than later adopters. First-to-solve creates durable lock-in. Foundational cohorts formed at launch persist even as new models emerge. Being first to users really matters!
We’re moving from “which model is smartest” to “which model fits my workflow.” Agentic inference is becoming the default. Something that has stuck with me: The report suggests it will soon exceed human inference in total volume – more “thinking” orchestrated by systems than typed by people. You read that right! WOW is all I can say.
🔬 Research Corner: NeurIPS Winners
Happy NeurIPS week to all those who celebrate! Below for a recap for the 4 winners of the NeurIPS 2025 Best Paper Awards:
Artificial Hivemind – Tested 70+ LLMs on open-ended prompts. Finding: severe mode collapse. Models keep repeating themselves, and different model families converge on the same responses. RLHF appears to be over-fitting to a “consensus” view of quality. Temperature and ensembles don’t fix it.
Gated Attention – Alibaba’s Qwen team won Best Paper for adding a learnable sigmoid gate after attention. Simple tweak, but it consistently improved performance, eliminated training loss spikes, and fixed the “attention sink” problem. Already in Qwen3-Next. Committee: “we expect this idea to be widely adopted.”
1000 Layer RL Networks – Most RL uses 2-5 layers. This team scaled to 1,024 layers for goal-reaching tasks with zero supervision – 2-50x performance gains. Depth can be a scaling dimension for RL, just like language models.
Why Diffusion Models Don’t Memorize – Two distinct training timescales: early phase learns to generate, later phase memorizes. The memorization phase scales linearly with dataset size, so larger datasets create a wider “safe” training window.
🆕 New Models & Other Bits + Bobs
Mistral 3 family – France’s AI champion released new models to keep pace. The European angle matters here: as US-China AI competition intensifies, Mistral is positioning itself as the “sovereign AI” option for enterprises that want frontier capabilities without geopolitical baggage. Whether that’s a real differentiator or just marketing remains to be seen.
DeepSeek V3.2 – Standard, Thinking, “Speciale” variants now live. 131K context at $0.28/$0.42 per million tokens. Reports of some of the chatter on it courtesy of Swyx via AINews: “Early user sentiment is mixed: some call V3.2 “frontier at last” while others find the chat UI experience underwhelming compared to benchmarks.” Sebastian Raschka wrote a great technical deep dive of DeepSeek models from V3 to V3.2, read it here.
AlphaFold’s next leap – DeepMind is merging AlphaFold’s atomic-precision protein predictions with LLM reasoning. Nobel laureate John Jumper describes it as combining sub-angstrom structural accuracy with hypothesis-generating capabilities. Five years after AlphaFold changed biology, the next phase is making it think – not just predict structures but generate scientific hypotheses about them. This is where AI-for-science gets really interesting.
OpenAI Confessions – New research on how “confessions” can keep language models honest. Worth a read for the alignment-curious.
🔮 So What Does This All Mean?
Three threads worth watching:
1. The “code red” tells us more than OpenAI wants. When you freeze revenue-generating features (ads, shopping) to focus on model quality, I think what you’re admitting is that the moat is the model, not the product. Or least, that superintelligence/AGI/whatever you want to call it, is the one and only true moat. And if Gemini 3 is genuinely better and Google has the potential to get there first – as Benioff and others suggest – that’s an existential problem, not a product problem.
2. Anthropic’s strategy is being validated. Enterprise-first, safety-forward, steady capability improvements over splashy consumer features. Now they’re preparing for potentially one of the largest tech IPOs ever while OpenAI is in crisis mode. The “boring” approach is looking pretty smart. Hats off to Dario and Daniela.
3. Agentic inference is the new battleground. The OpenRouter data shows 50% of inference is now reasoning models. AWS is shipping agents that work for days. Anthropic’s Snowflake deal is explicitly about “agentic AI.” This is where the next phase of competition happens – not chatbots, but systems that actually do work end-to-end.
What I’m watching ahead of the new year:
Any Garlic leaks or timeline clarity from OpenAI
Enterprise adoption signals for Opus 4.5 vs. Gemini 3
More detail on Anthropic’s IPO timeline
‘til next week friends!
—Jess
This was a really good rundown!
That OpenRouter stat about reasoning models hitting 50% of inference is nuts when you think about it. A year ago we were basically at zero. The shift from "answer questions" to "actually work through problems" happened way faster than most people expected, and I think that's what's really freaking everyone out about the Gemini 3 vs GPT competition.