


The past 10 days have revealed a transformative shift in the AI landscape: OpenAI’s GPT-4o mini release made costs plummet by 60% with their cost-efficient small model; Llama 3.1 405B has released an open source model that is state-of-the-art, pushing open source to the frontier; and Mistral has further pushed the barrier with Mistral Large 2, delivering a strong open source model with inference efficiency at its core.
Importantly, these changes are taking place in short time cycles. GPT-4 was released in 2023 and cost $37.5/1M tokens. Merely one year later in May 2024, OpenAI released GPT-4o, and cut the cost from $37.5 to $7.5/1M token – a whopping 80% decrease in costs in a period of a year. And the cycles just keep getting shorter. Just two months after the flagship GPT-4o release in May, OpenAI released a few days back GPT-4o mini – a smaller model than the flagship 4o, but the performance is nonetheless impressive, and the cost is a surprisingly low $0.3/1M tokens.
Let’s look at the chart below. If we compare the right hand side to the left hand side, we see that the left hand side has the same intelligence for significantly better price points. Notably, the right-hand side includes models that were considered state-of-the-art a mere three months ago. The cost of intelligence just keeps getting smaller – while the models themselves keep getting better.

Chart source: Swyx’ excellent twitter thread on “The <100B Model Red Wedding” (worth a read in full!)
This remarkable rate of change means this isn't incremental progress—it's a dramatic leap towards intelligence becoming "too cheap to meter." For startups, this presents an unprecedented opportunity to leapfrog established players.
Let's dive into why this AI price crash is the key to unlocking the next wave of startup-led innovation, and how it's leveling the playing field in ways we've never seen before.
The Foundation Model Race: A New Paradigm for Intelligence Scaling
Recent AI model releases are establishing a new paradigm for scaling intelligence:
GPT-4o mini: OpenAI's most cost-effective model, priced at 15 cents per million input tokens and 60 cents per million output tokens. Its 82% score on the MMLU benchmark demonstrates strong performance across various domains. The significant cost reduction (60%!) compared to GPT-3.5 Turbo highlights the rapid progress in model efficiency.
Llama 3.1: Meta's open-source release includes a frontier model with 405 billion parameters. Llama 3.1's performance on various benchmarks showcases the narrowing gap between open-source and proprietary models and indeed by multiple metrics, Llama 3.1 405B is the new state-of-the-art foundation model.
Mistral Large 2: With 123 billion parameters, this model exemplifies how architectural innovations can lead to performance comparable to much larger models. Mistral's focus on inference efficiency is particularly relevant for practical applications.

Chart source: Mistral
The Path to $0 Intelligence: Cloud Wars and the Democratization of AI
A critical factor driving the declining cost of intelligence is the intensifying competition among cloud providers. This "Cloud War" is having profound implications:
Race to the Bottom on Pricing: As major players like AWS, Google Cloud, and Azure compete, they're continuously dropping prices for AI services.
Increased Accessibility: Cloud providers are simplifying AI deployment, making advanced capabilities available to companies of all sizes.
Specialized AI Hardware: Competition is driving investment in custom AI chips and infrastructure, further reducing costs.
The result of all of this is a virtuous cycle: Cloud Wars → Declining Cost of Intelligence → Huge Advantage for Startups → Build Agents w/ Auto Upgrading → Delivery Enterprise ROI → Generate Infra Demand

Architectural Agility as the Edge:
This virtuous cycle is reshaping the competitive landscape, giving startups unprecedented benefits. This is one of the key reasons why staying “GPU poor” can be a competitive advantage. The pace of innovation and cost cutting is moving so far that flexibility is paramount. Startups that design their architecture in such a way that allows them to easily leverage the newest model release at the frontier of cost, efficiency, and performance, will have a strong advantage. In particular, here are some of the points we advise founders to consider as they design their products:
For most startups, apply the "Hot Swapping" paradigm and design for interchangeability as your go-to architecture:
Build a flexible architecture that allows easy integration of new language models (e.g., GPT-N, Llama N) as they become available.
This approach enables companies to continually leverage state-of-the-art models without major infrastructure changes.
For the advanced users (>10M tokens generated/month), implement a tiered approach to model usage:
Continue using frontier models for complex, high-value tasks where performance is critical.
For frequent, simpler tasks, consider optimizing:
Implement clever caching strategies to reduce API calls.
Fine-tune prompt engineering to minimize token usage.
As your company's resources increase and engineering org advances:
Explore techniques like knowledge distillation to create smaller, task-specific models.
This advanced optimization step should be considered only when the potential efficiency gains justify the significant investment.
David Zhang, CEO of Aomni (an AI platform for sales, and one of our portfolio companies), summarizes these points best in his post around the compounding benefits of intelligence trending towards zero:
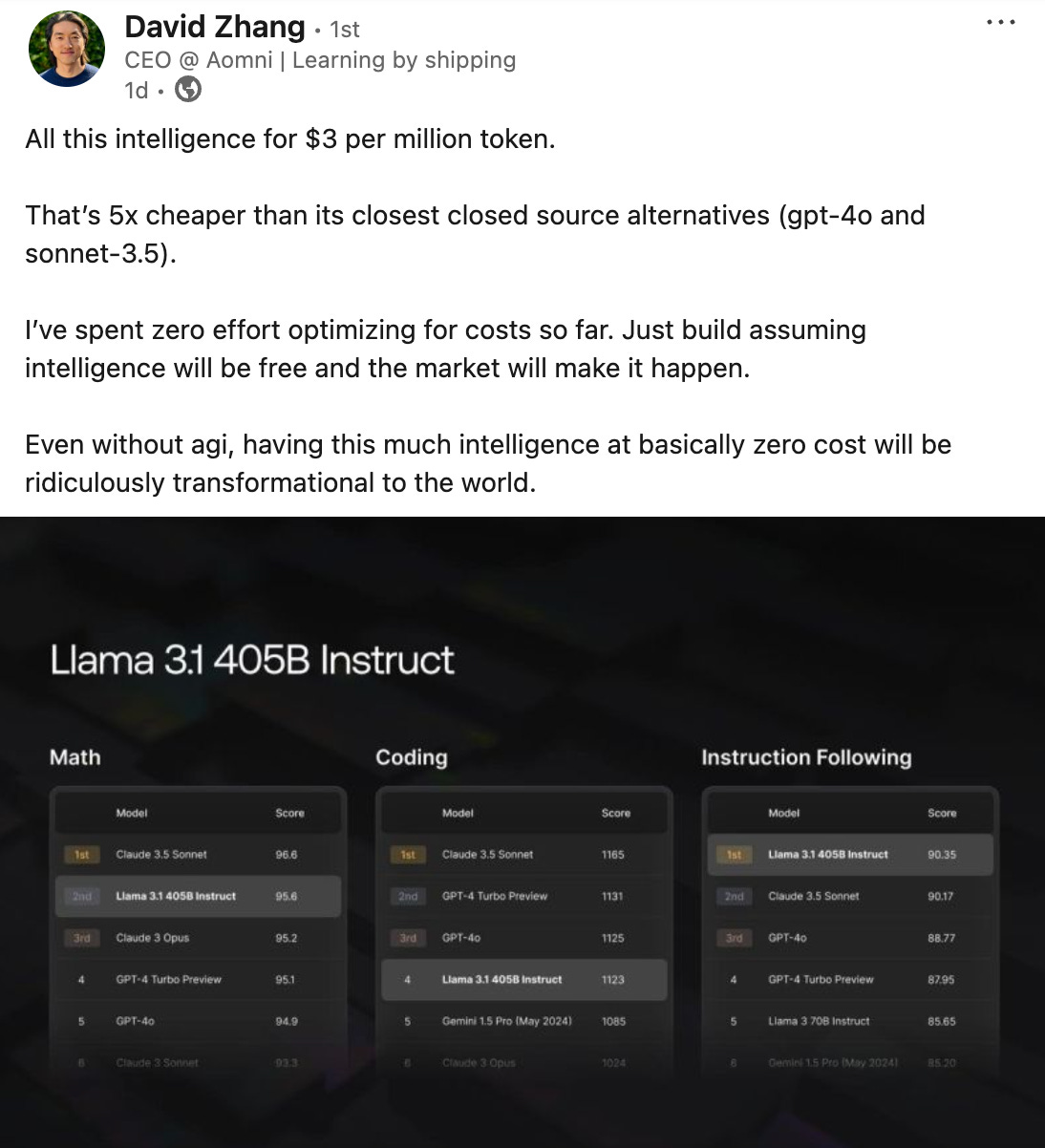
The New Startup Playbook: Intelligence as a Utility
As AI capabilities become more accessible, we're moving towards a new paradigm:
The API Economy Evolution: AI services will become core components of software architecture.
"Intelligence Too Cheap to Meter": As AI capabilities become ubiquitous and nearly free, the focus will shift from cost to value creation. Startups that can innovate on top of this "free" intelligence layer will thrive.
The New Oil vs. the New Electricity: While data has been called the new oil, AI is becoming the new electricity - an essential utility powering innovation across all sectors.
As cloud providers compete and AI costs plummet, startups are uniquely positioned to win. By building agile, AI-native solutions that automatically leverage the best available technologies, new companies can outmaneuver larger, slower-moving competitors.
The future belongs to those who can ride this wave of ever-cheaper intelligence, turning rapidly advancing AI capabilities into real-world value. For startups, there has never been a better time to enter the AI race. The intelligence revolution is here, and it's too cheap to ignore.
"The future belongs to those who can ride this wave of ever-cheaper intelligence, turning rapidly advancing AI capabilities into real-world value" >>> This!