
The New Computer: A Platform War for Personal AI
Jensen says OpenClaw is as big as Linux. Four desktop agents shipped in two weeks. The race to own this layer is on.

Okay so. GTC week!! Jensen came out in the leather jacket (obviously) and told 30,000 people that every company on earth needs an “OpenClaw strategy” – then unveiled NemoClaw, an enterprise security layer around the very tool he’s telling everyone to adopt. In case you were wondering, the lobster is here to stay!

He also announced data centers in space (solar-powered orbital AI compute, shipping 2027!), a nuclear reactor partnership with AtkinsRealis, seven new automakers joining the robotaxi platform, and a $1B drug discovery lab with Eli Lilly. Physical AI was the definitely a headline. So. Many. Launches!!!
Meanwhile, OpenAI’s Codex crossed 2M weekly active users (!!!), Fidji Simo said the words “we cannot miss this moment because we are distracted by side quests” (they’re killing the standalone Sora app!), and then shipped GPT-5.4 mini and nano – which are great but cost up to 4x more than their predecessors. OpenAI also abandoned building its own data centers and pivoted Stargate to ~$600B in rented compute. Cursor shipped Composer 2 and within 24 hours got caught – their “in-house model” turned out to be Moonshot’s Kimi K2.5 with a fine-tune and missing attribution. Anthropic made Claude’s 1M context window generally available and launched Dispatch, which lets you control your Mac from your phone through Cowork. Manus (now owned by Meta) dropped a desktop agent app. Microsoft is reportedly considering suing both Amazon and OpenAI over a $50B cloud deal, which, wow. Mistral showed up at GTC with Forge and Small 4.
And there’s more! I’ll stop writing or the intro will be a blog on its own. It was a LOT.

This week’s main thread: the platform war for personal AI. Jensen called OpenClaw “as big as Linux” and said every company needs an OpenClaw strategy. Four different companies shipped four different desktop agents within two weeks – NemoClaw, Dispatch, Manus My Computer, Perplexity Personal Computer – all trying to own the layer between the model and your machine. The models are table stakes. The fight is over the orchestration layer.
Anywhooo, a lot to get into, lezzz go:
📋 This Week’s Cheat Sheet
🏗️ Jensen says Nvidia expects $1T+ in chip sales – through end of 2027, up from $500B forecast; Vera Rubin delivers 60 exaflops; NemoClaw wraps OpenClaw in enterprise security; physical AI is the next trillion-dollar market
💻 Codex hits 2M+ weekly active users – API usage up 20% post-GPT-5.4; subagents now live in Codex app and CLI; OpenAI killing “side quests” like Sora; $10B PE joint venture with TPG, Advent, Bain, Brookfield
🤖 GPT-5.4 mini and nano ship – near-flagship performance, 400K context, but up to 4x pricier than predecessors; mini becomes default for background coding and subagent fan-out
⚖️ Microsoft may sue OpenAI and Amazon – $50B AWS deal potentially violates Azure API exclusivity; “Stateful Runtime Environment” vs. stateless API calls is the legal crux
🧠 Claude’s 1M context window goes GA – flat pricing across the full window (no long-context multiplier!); 78.3% on MRCR v2, 3x better than Gemini at 1M; 600 images per request
🖥️ The desktop agent wave hits – Dispatch, Manus My Computer, Perplexity Personal Computer, NemoClaw: four products, one week, all controlling your actual computer
🔨 Mistral Forge debuts at GTC – full-cycle model training for enterprises; Mistral Small 4 (119B params, 8B active) ships Apache 2.0 with 256K context
🏗️ NVIDIA GTC: Jensen Wants to Own Everything
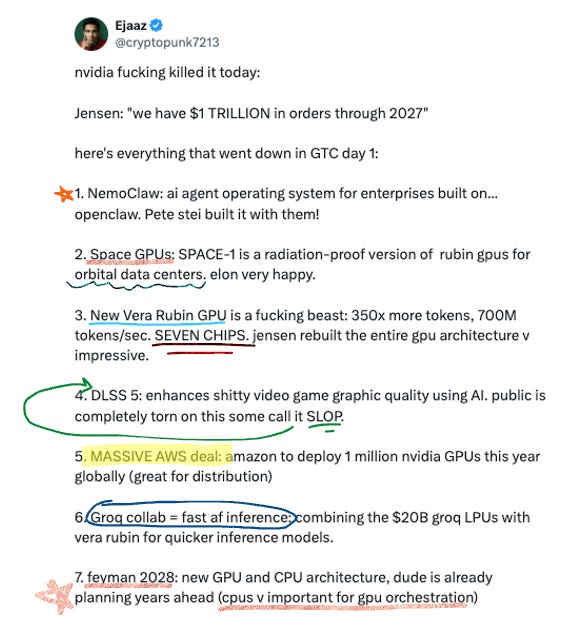
GTC was absurd this year. 30,000 attendees, 190+ countries, and Jensen announced a very casual $1 trillion+ revenue (I meeean!) forecast for AI chip sales through end of 2027 – up from the previous $500B through 2026. Wall Street consensus was around $835B so he’s out ahead of his own analysts!! The numbers:
FY2026 revenue: $215.9B (up 65% YoY)
Q1 FY2027 guidance: $78B
$1T+ through 2027, vs. $500B prior forecast
Literally trillions!!

The hardware centerpiece is Vera Rubin – seven chips, five rack types, one AI supercomputer (”the POD”). At full scale: 40 racks, 1.2 quadrillion transistors, 1,152 Rubin GPUs, 60 exaflops of compute. Up to 10x inference cost reduction versus Blackwell. Partner deployments start H2 2026 across AWS, Google Cloud, Microsoft, CoreWeave, and others.
The other BFD release: Groq 3 LPX – NVIDIA’s first non-GPU rack ever. Dedicated inference hardware from their ~$20B Groq acquisition. It splits prefill (Rubin GPUs) from token decode (Groq LPUs), and the claimed numbers are hardcore:
35x higher throughput than Blackwell NVL72 on trillion-parameter models
1,500 tokens/sec target for agentic workloads
Production ships Q3 2026
Big “if they hold up” energy on those numbers. But still!
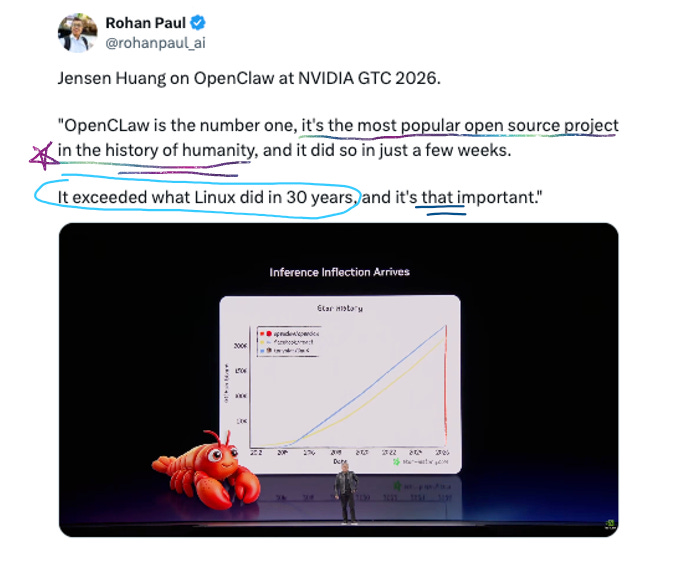
Then NemoClaw. Ahhh OpenClaw is the gift that keeps on giving, isn’t it. Jensen brought OpenClaw creator Peter Steinberger on stage and the framing was very intentional. OpenClaw is huge – 250K GitHub stars in 60 days, fastest-growing open-source project in history – but it also has serious security problems:
One-click remote code execution CVE
10.8% of ClawHub plugins found to be malicious
Google banned paying subscribers from using it
Meta prohibited it on work devices
NemoClaw is NVIDIA’s answer: an open-source stack that wraps OpenClaw in enterprise-grade sandboxing. Kernel-level sandbox, out-of-process policy engine, privacy router that keeps sensitive data on local Nemotron models.
Jensen on stage:
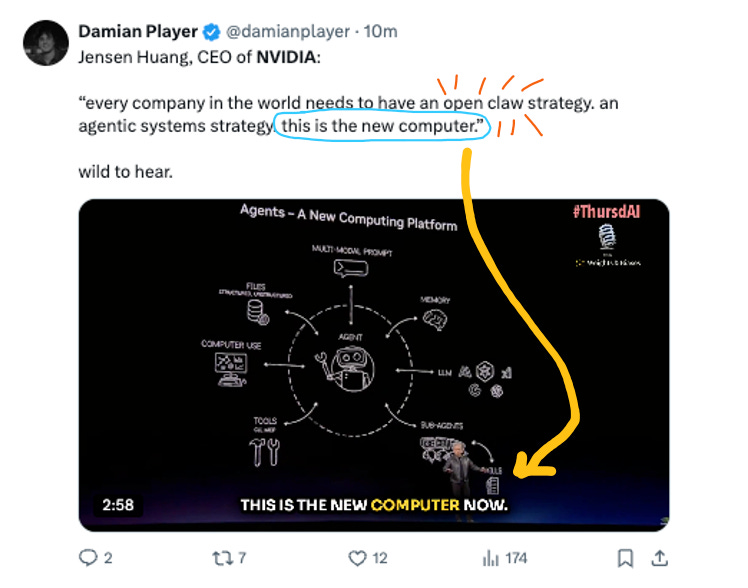
“Mac and Windows are the operating systems for the personal computer. OpenClaw is the operating system for personal AI.”
My dudes and dudesses - this is a big capital S Statement! I have a whole section later in this blog on the desktop agent wave, but suffice to say this is a huge theme and I expect our next significant category of AI launches. Every company will indeed need to have their own OpenClaw strategy, and what remains to be seen is if this will be build or buy… and thus how startups can serve this new wave!
Let’s Get Physical

Apart from the new computer, the physical AI push was also a real headline of this GTC – Jensen framed it as NVIDIA’s next trillion-dollar market. His thesis: every industrial company will become a robotics company, and NVIDIA wants to turn robotics’ data problem into a compute problem (simulation and synthetic data instead of expensive real-world collection).
Space: Yes, space is coming, baby!!! (Yes yes yes, you all know it’s my secret favorite topic 🪐🪐) NVIDIA announced Space-1 Vera Rubin modules – space-hardened AI compute for orbital data centers, solar-powered, shipping 2027. Six aerospace partners confirmed:
Axiom Space (which already launched a prototype orbital data center unit to the ISS)
StarCloud (sent an H100 to orbit in November)
Aetherflux
Kepler Communications
Planet Labs
Sophia Space
Jensen acknowledged the economics are poor today but said intelligence must exist wherever data is generated:
“AI processing across space and ground systems enables real-time sensing, decision-making and autonomy, transforming orbital data centers into instruments of discovery and spacecraft into self-navigating systems.”
Autonomous vehicles: Seven new automakers joined the NVIDIA RoboTaxi Ready platform: BYD, Hyundai, Nissan, Geely, Isuzu, joining Mercedes, Toyota, and GM.
Combined: ~18 million vehicles per year. The new Alpamayo 1.5 model lets vehicles reason and narrate decisions in natural language – the live demo showed a car explaining a lane change on request. Also look out for: Uber robotaxis launching LA and SF in 2027, expanding to 28 cities on four continents by 2028.

Robotics and industrial AI: GR00T N2 (humanoid model) completes new tasks in unfamiliar environments 2x more often than leading alternatives. ABB, FANUC, YASKAWA, and KUKA (combined: 2M+ installed robots) are integrating Omniverse simulation. KION is running autonomous forklifts in a live pilot with Siemens and Accenture. Disney’s Olaf showed up on stage driven by NVIDIA’s physics engine – with free-roaming AI characters coming to Disneyland Paris later this month.
Energy and infrastructure: NVIDIA partnered with AtkinsRealis on nuclear-powered AI data centers using CANDU reactors and SMRs. They announced the DSX AI Factory reference design – a blueprint for gigawatt-class data centers (a single one requires a nuclear reactor’s worth of power). DSX Flex software lets AI factories act as grid-flexible assets, claiming to unlock 100 GW of stranded grid power. Eco Wave Power demoed a wave energy digital twin. Jensen’s stat: energy efficiency in LLM inference has improved 100,000x in the past 10 years.
Healthcare: Eli Lilly announced up to $1B co-innovation AI lab over 5 years for drug discovery. Roche deployed 3,500+ Blackwell GPUs across hybrid cloud. New surgical AI suite: Open-H (700+ hours surgical video), Cosmos-H (synthetic surgical data), GR00T-H (VLA model for clinical instructions). I think this is very cool. We should be using AI to bring much more innovation to pharma & healthcare delivery!
A few more from the keynote:
KVTC (KV Cache Transform Coding) shrinks LLM memory overhead by 20x without changing model weights – applies media compression principles (basically JPEG for KV caches) and cuts time-to-first-token by 8x on H100. Published at ICLR 2026. Huge for long-context agentic workloads.
H200 sales restart in China – confirmed orders from ByteDance, Tencent, Alibaba, and DeepSeek. CFO had previously guided zero China datacenter revenue in Q1, so this is all upside.
DLSS 5 uses generative AI to reconstruct full frames in real time. Ships fall 2026 on RTX 50-series.
CloudXR 6.0 streams 4K at 120Hz to Apple Vision Pro natively. BMW, Kia, Rivian, and Volvo already using it for design review.
NVIDIA is positioning itself as the full-stack provider for the physical world – chips, inference hardware, agent orchestration, orbital compute, autonomous vehicles, industrial digital twins, drug discovery, energy infrastructure. Jensen’s five-layer vision: energy > chips > infrastructure > models > physical AI. They want all of it. 👇

💻 OpenAI: Codex Numbers, Subagents, and the Death of Side Quests
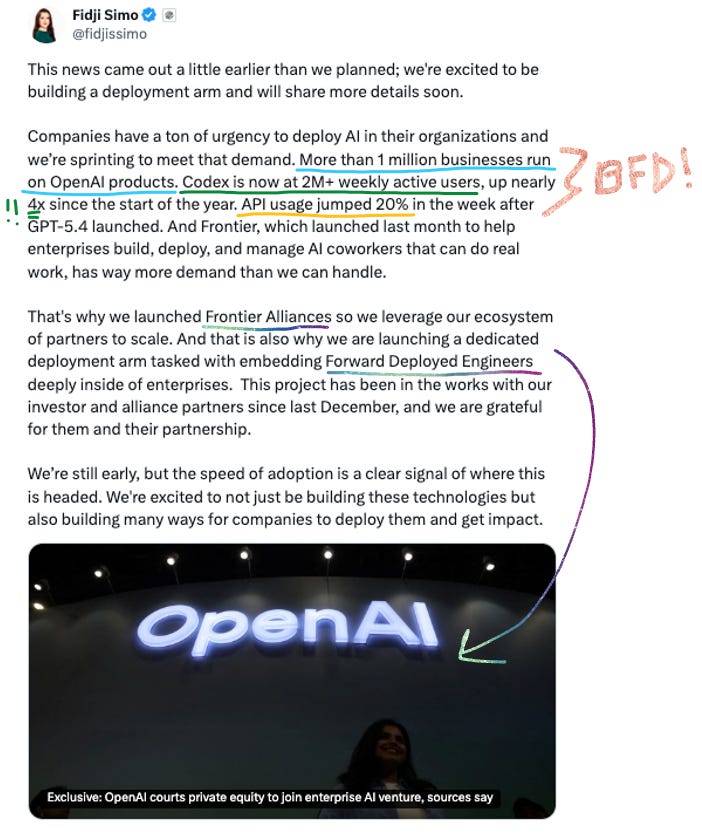
Codex crossed 2M weekly active users – up nearly 4x since the start of 2026. API usage jumped 20% the week after GPT-5.4 launched. Enterprise now accounts for $10B of OpenAI’s $25B total ARR.
Fidji Simo’s framing was blunt: “We cannot miss this moment because we are distracted by side quests.”

They’re killing standalone products like the Sora app (100K downloads on day one > 45% drop in monthly installs by January, wooof!) to focus compute on Codex and the Frontier platform.
Subagents
“Codex can run subagent workflows by spawning specialized agents in parallel and then collecting their results in one response. This can be particularly helpful for complex tasks that are highly parallel, such as codebase exploration or implementing a multi-step feature plan.”
Subagents are now live in both the Codex app and CLI. The idea: Codex spawns specialized agents in parallel – an explorer, a worker, etc. – then collects results back. Think PR review where one agent analyzes code, another checks security, a third consults docs, all at once. You define custom agents in TOML files. They only spawn when asked (not automatic), depth limit of 1 – child agents can’t spawn more children. (Yet!!!)
Stargate Pivots to Rented Compute
This got buried in a busy news week but it’s a pretty big deal. OpenAI abandoned plans to build its own data centers (after all that!!!!) and reorganized Stargate into three groups: technical design, commercial partnerships, and facility operations. The new strategy: ~$600B in rented compute through 2030 from AWS, Google Cloud, AMD, and Cerebras. That is a massive commitment to other people’s infrastructure, and a pretty clear signal that OpenAI decided the economics of building its own data centers didn’t work. After all that jelly, no toast!!?!

Private Equity Comes for AI
A $10B joint venture with TPG, Advent International, Bain Capital, and Brookfield to deploy the Frontier platform across PE portfolio companies. All four firms get board seats. Anthropic is reportedly in parallel talks with Blackstone, Permira, and Hellman & Friedman for a similar deal with Claude. PE firms want AI deployed across their portfolios yesterday and they’re willing to write very large checks to make it happen.
🖥️ The Desktop Agent Wave
Okay, so going back to OpenClaw (I know, I know, #OpenClaw4Ever woohoo). This is the thing that ties half the week together. Four different companies launched four different products that all do roughly the same thing: AI agents that don’t just talk to you but actually control your computer.
Jensen at GTC: “Mac and Windows are the operating systems for the personal computer. OpenClaw is the operating system for personal AI.” As Ben Thompson put it, despite agents like OpenClaw running locally, the actual AI inference still happens in the cloud – agents are the logical extension of the thin client model.
Here’s where we are right now:
NemoClaw (NVIDIA): enterprise security wrapper for OpenClaw. Kernel-level sandbox, policy engine, privacy router. The enterprise play.
Dispatch (Anthropic): control your Mac from your phone through Claude Cowork. QR pairing, end-to-end encrypted, sandboxed permission model. Reports from local spreadsheets, draft briefings from Slack and email, build presentations from Drive. Max subscribers first, Pro within days. The closed-and-controlled play.
My Computer (Manus / Meta): desktop agent that runs locally – CLI commands, file editing, app control. Uses the Manus 1.6 model family (Lite, standard, Max). The Meta-resources play.
Personal Computer (Perplexity): software that turns a Mac mini into an always-on AI agent. Runs 24/7, works across local files, apps, and sessions. $200/month. Perplexity CEO Aravind Srinivas: “A traditional OS takes instructions. An AI OS takes objectives.” The always-on play.
Here was one cool take I read on My Computer, but really the broader circled portion is the point I’m trying to make:
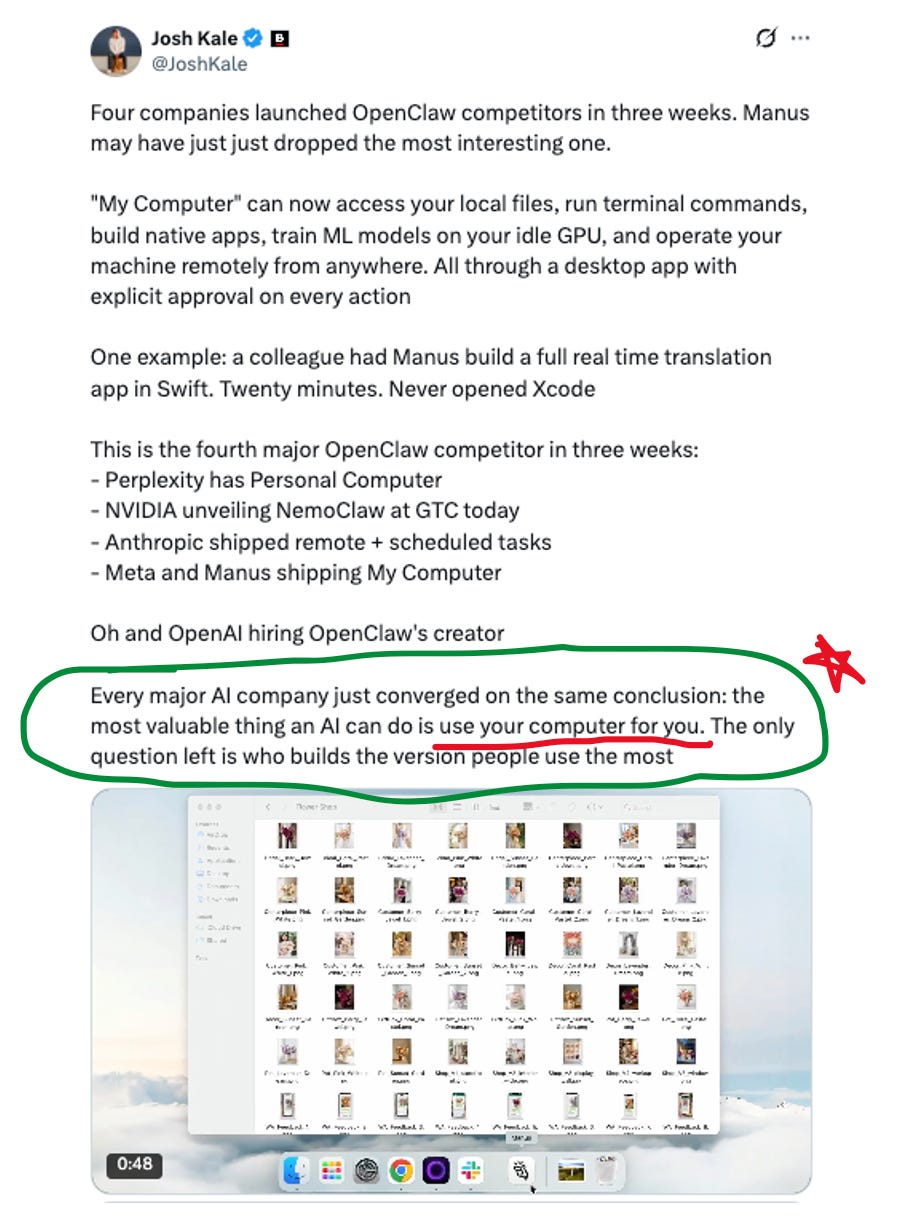
The security question looms over all of this. Simon Willison has been warning about what he calls the “lethal trifecta” – when an agent combines access to private data, exposure to untrusted content, and the ability to communicate externally, it becomes vulnerable by design. OpenClaw, in its default configuration, does all three. NemoClaw and Dispatch exist specifically because this problem is real.
PCWorld’s view is that among the big three AI providers, Anthropic is “arguably the furthest along in terms of turning the Claude app into an agentic AI command center,” with Google and OpenAI “scrambling to catch up.” Whether you agree with that framing or not, Jensen’s keynote and the recent launches do confirm one thing: the category is here and it’s moving fast.
🤖 GPT-5.4 Mini and Nano
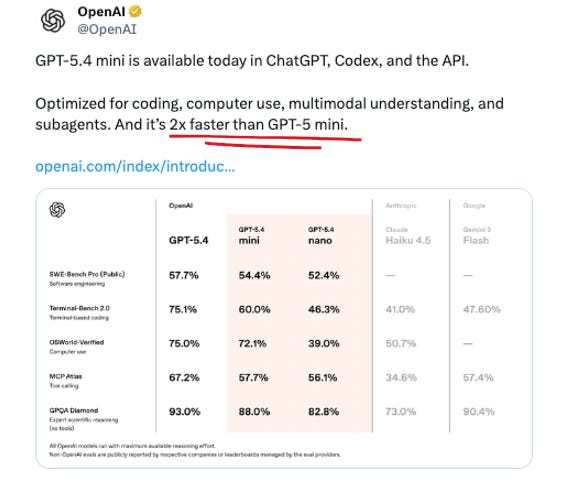
OpenAI shipped these on March 17 and they’re good! Mini is 2x faster than GPT-5 mini, handles coding, computer use, multimodal understanding, and subagents, with a 400K context window. Approaches full GPT-5.4 performance on SWE-Bench Pro (54.4% vs 57.7%) and OSWorld (72.1% vs 75.0%), and uses only 30% of GPT-5.4’s Codex quota – making it the new default for a lot of background coding workflows.
The catch: pricing.

Mini: $0.75/$4.50 per million tokens (input/output) – previous gen was $0.25/$2.00. That’s 3x on input, 2.25x on output.
Nano: $0.20/$1.25, up from $0.05/$0.40 – a 4x hike on input
These are meaningfully better models than their predecessors – near-flagship quality at a fraction of the compute. But the pricing signals where OpenAI is going: the era of racing to the bottom on per-token cost is over. They’ve got the usage numbers to charge more and they’re charging more.
 - S06E08 Comedy | Video gifs by quotes | 8417882c | 紗")
⚖️ Microsoft’s $50B Problem

Shots fired!!! Microsoft is considering legal action against Amazon and OpenAI over a $50B cloud deal.
Quick background:
Last October: Microsoft signed off on OpenAI’s restructuring, gave up exclusive cloud-hosting rights, but kept a clause requiring all API access to flow through Azure
February: AWS invested $50B in OpenAI, became “exclusive third-party cloud provider” for Frontier
Microsoft: excuuuuse me???
The technical crux is fun. OpenAI and Amazon built a “Stateful Runtime Environment” on AWS Bedrock – a wrapper that adds persistent context, memory, identity, and permissions to OpenAI’s models. Their argument: it’s stateful, so it falls outside Microsoft’s monopoly on stateless API calls. Hmmmm! 🤔🤔
Microsoft’s position: you can’t run a functional enterprise system at this scale without stateless API calls underneath, no matter what you call the wrapper.
A Microsoft insider told the Financial Times: “We know our contract, and we’ll sue them if they breach it.”
Azure is a $75B/year business. OpenAI is reportedly planning an IPO at ~$1T valuation – a lawsuit would complicate that considerably. The three companies are still negotiating. So that’s fun!!
🧠 Claude’s 1M Context Window Goes GA
Anthropic made the 1M context window generally available on March 13 for Opus 4.6 and Sonnet 4.6. The headline is the pricing: flat rates across the entire window. A 900K-token request costs the same per-token as a 9K request. No multipliers, no beta headers required.
This matters because neither OpenAI nor Google does this. GPT-5.4 charges a 2x/1.5x premium above 272K tokens. Google charges extra above 200K. Claude is the only frontier model family offering 1M at flat rates.
Howeeeeeeever – Gemini has had 1M context since February 2024 (and 2M via API!). GPT-5.4 hit 1.05M tokens two weeks ago. So Anthropic isn’t first to 1M by a long shot. What they are claiming is that their 1M context actually works: Opus 4.6 scores 78.3% on MRCR v2 (multi-needle retrieval at 1M tokens), versus 26.3% for Gemini 3 Pro on the same test. That’s a 3x gap. They also bumped media limits to 600 images per request – up 6x from 100.
The counterpoint, via AINews: it’s been two full years since 1M context was theoretically possible, and context windows are growing far slower than every other dimension of model capability (cost, speed, quality). They attribute this to a global memory shortage and predict context windows won’t meaningfully exceed 1M in the next two years.
Which puts us in an interesting place, in terms of what it means for infrastructure and the applications that can be built on top of AI; if indeed it is true that the models keep getting smarter but the context window is now hitting a wall.
🔨 Mistral Forge + Small 4
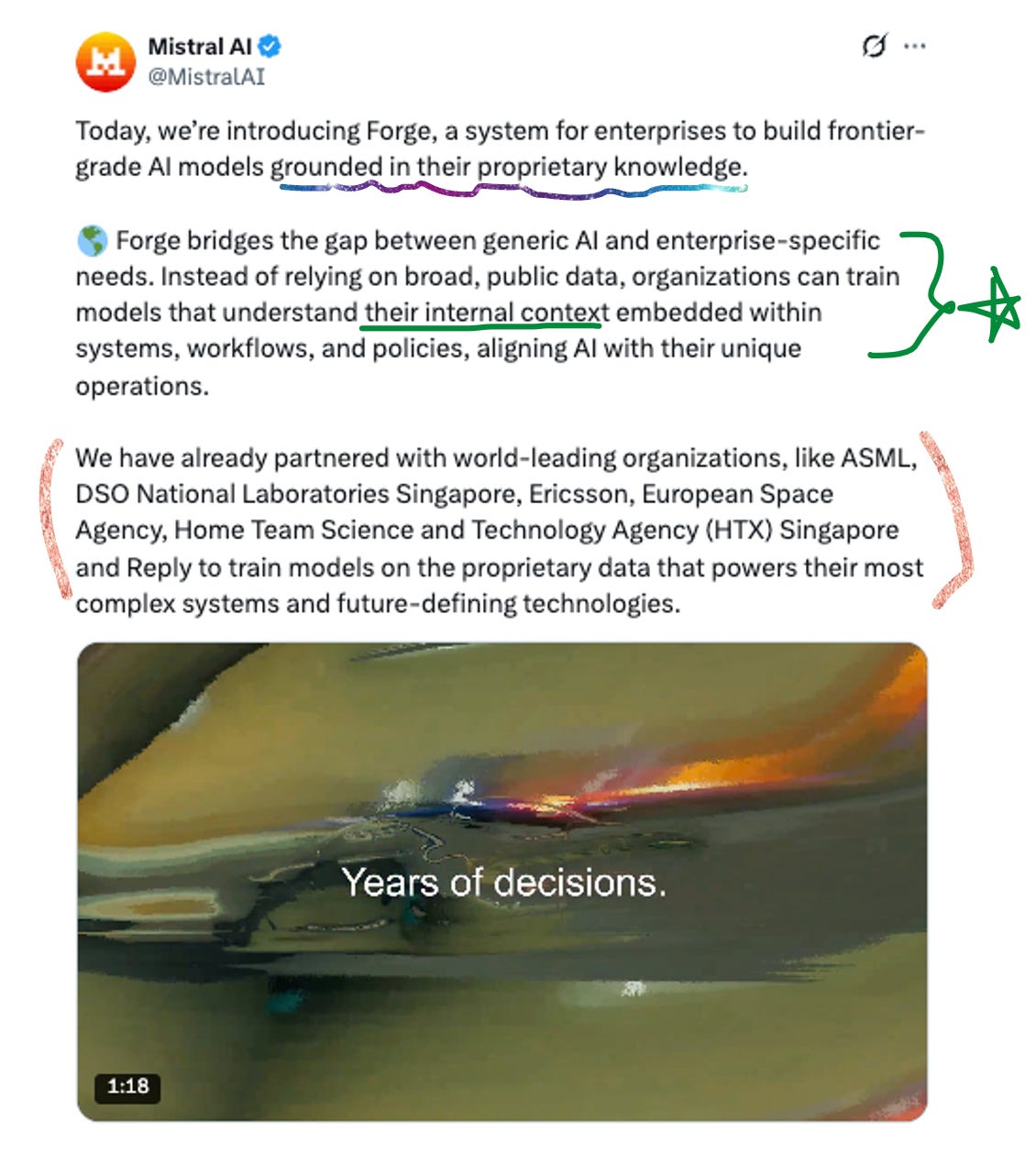
Mistral is making a sovereignty play. At GTC they launched Forge – a platform for full-cycle model development. Not just fine-tuning, but proprietary pre-training, post-training (SFT, DPO, ODPO), and RL pipelines on your own data. Forward-deployed Mistral engineers embed with customers. Early adopters: ASML, Ericsson, European Space Agency. Target sectors: finance, defense, government – places where you literally can’t send your data to someone else’s cloud.
Mistral Small 4 was also fairly significant release, that kinda fell under the radar:
119B total parameters, 8B active (MoE)
Apache 2.0, 256K context
Unifies three previous models (Magistral for reasoning, Devstral for code, Mistral Small for instruct) into one
reasoning_effort toggle – “none” for fast chat, “high” for deep reasoning
40% faster completions, 3x throughput versus Small 3

And then Leanstral – the first open-source code agent for Lean 4 formal proof verification. It generates code WITH mathematical proofs that the Lean type checker verifies automatically. Cost comparison on FLTEval: Leanstral scores 26.3 at pass@2 for $36 in compute. Claude Opus 4.6 scores 39.6 at pass@4 for $1,650. Love to see me some cost efficiency!
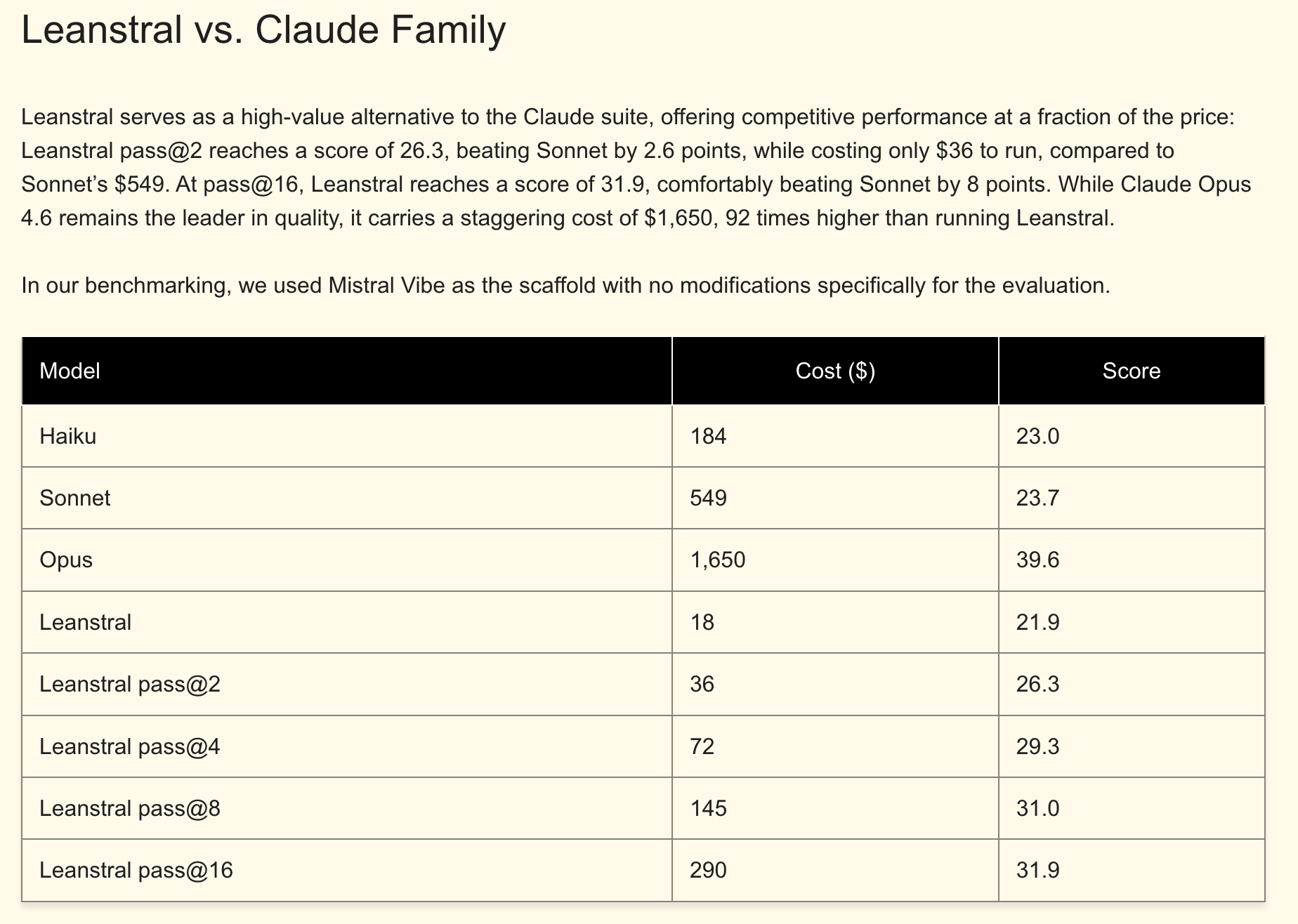
Mistral’s CEO says they’ll cross EUR 1B in revenue by year-end (they were at ~$400M ARR in January). NVIDIA is co-developing the next Nemotron base model through the Nemotron Coalition.
💻 Cursor Ships Composer 2 (and Gets Caught)

Cursor launched Composer 2 on March 19 – their third in-house coding model in five months. It’s code-only (cofounder Aman Sanger: it “won’t help you do your taxes”), purpose-built for multi-file edits, terminal interaction, and long-horizon agentic tasks. The numbers are strong:
CursorBench: 61.3 (up from 44.2 on Composer 1.5)
SWE-bench Multilingual: 73.7 (up from 65.9)
200K context window
~86% cheaper than Composer 1.5 — API pricing at $0.50/$2.50 per million tokens (standard), vs Opus 4.6 at $5/$25
The interesting training detail: they introduced “compaction-in-the-loop” RL, where the model pauses mid-generation to self-summarize its context down to ~1,000 tokens when it hits length triggers. Clever approach to the long-horizon problem.
Then the drama. Within 24 hours of launch, a developer discovered that the internal model ID was kimi-k2p5-rl-0317 – revealing Composer 2 is built on Kimi K2.5, the open-weight model from Moonshot AI (same Moonshot whose Attention Residuals paper is in Bits & Bobs below!). Moonshot’s Head of Pretraining publicly confirmed the tokenizer was identical and asked why Cursor wasn’t respecting the license terms. Kimi K2.5’s modified MIT license requires products exceeding $20M in monthly revenue to prominently display “Kimi K2.5” in the UI. Cursor exceeds that threshold by roughly 8x.

The situation appears resolved — Kimi posted congratulations (see screenshot above), noting Cursor accesses the model through Fireworks AI’s hosted RL platform as part of an authorized commercial partnership. But the optics of launching an “in-house model” that turns out to be a fine-tuned Chinese open-weight model with missing attribution were... not ideal. As one comment put it on the Kimi statement:

Worth noting: independent testing from The New Stack showed Claude Code completing an identical task using ~33K tokens vs Cursor Agent’s ~188K tokens — a 5.5x efficiency gap. Cheaper per token, but using a lot more of them.
AI Drama of the Week: SOC2 That SOCs Very (!) Much
More drama! Errrr, I’m going to leave this here with minimal notes. I mean really, there’s so much drama in AI I do really feel like I’m writing a screenplay at times.
Spend Your Tokens!
I think we’ll be seeing a lot more of these messages! Consume your tokens!
🔬 Bits & Bobs
📐 Moonshot’s Attention Residuals – the clearest technical paper this week. Kimi replaces fixed residual connections in Transformers with input-dependent attention over the depth dimension – each layer selectively aggregates earlier representations instead of blindly accumulating everything. Results on Kimi Linear (48B total, 3B active): 1.25x compute advantage, <2% inference latency overhead, +7.5 on GPQA-Diamond. MIT’s Ziming Liu wrote a detailed analysis noting the No-Free-Lunch tradeoff.
🛠️ Code-executing agents are becoming real infrastructure – a bunch of stuff shipped this week all pointing the same direction:
LangSmith Sandboxes: secure ephemeral code execution in hardware-virtualized microVMs
Open SWE: open-source background coding agent patterned after internal systems at Stripe, Ramp, and Coinbase (integrates with Slack, Linear, GitHub)
Docker + NanoClaw: one-command OpenClaw deployment in MicroVM sandboxes – relevant given 41% of OpenClaw skills were found to have vulnerabilities
LangChain crossed 1B framework downloads and joined the Nemotron Coalition
The whole stack is shifting from “can the agent write code” to “can we safely deploy the agent that writes code.” Sandboxing isn’t optional anymore!!
📱 Google upgrades Stitch to a voice-enabled canvas with instant UI prototyping – you speak to the canvas (powered by Gemini Live), get real-time design critiques, and watch it auto-generate screens as you prototype. Exports clean HTML/CSS and can generate working React apps. They’re calling it “vibe design” (start from business objectives and vibes, not wireframes).
🔮 Parting Thoughts
Lots of big swings this week and I think I’ve made my point that the personal agent revolution is here to come. But really, what stays with me as I reflect on this week is NVIDIA’s contrast with everyone else.
OpenAI is killing Sora, reorganizing Stargate, renting $600B in compute, and sending PE firms to deploy Frontier. 🥱 Cursor tried shipping someone else's model under its own name. 🤨 Microsoft is lawyering up over API routing. Etc etc.
All very much fighting over today's landscape.
Jensen walked on stage and talked about nuclear reactors and data centers in orbit.
🚀🚀 Different timescale and energy entirely.
‘tiiiil next week!
-Jess 🦁
“…who builds the version that people use.” The winner is the new Windows.